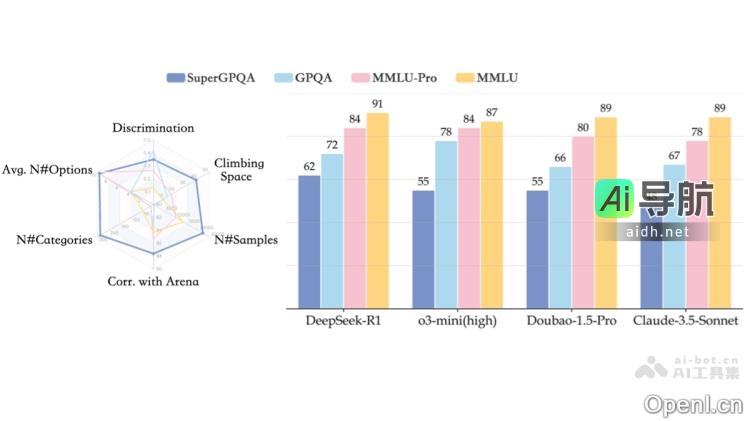
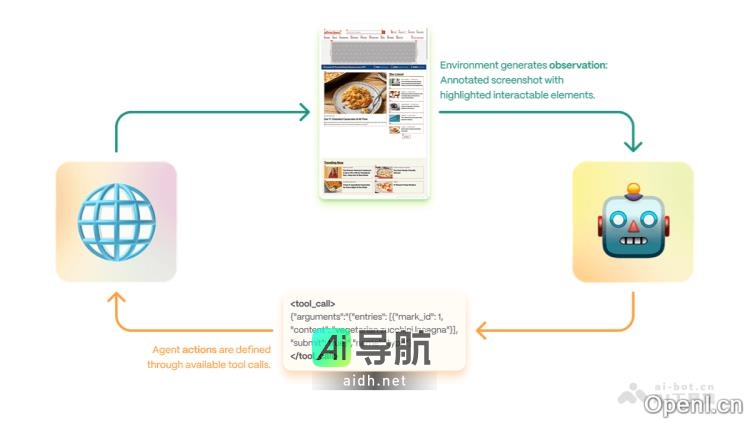
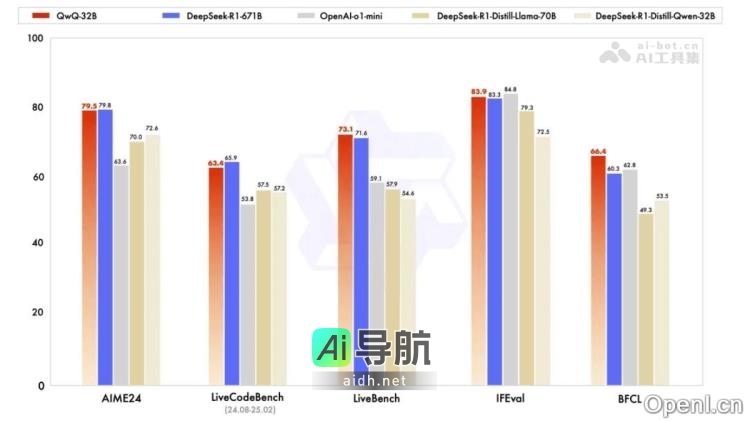
Proxy Lite 是一款开源的轻量级视觉语言模型(VLM),其参数数量为 3B,专注于自动化网页操作。该模型能够像人类一样执行浏览器操作,包括网页交互、数据抓取和表单填写等重复性任务,从而显著降低自动化成本。它采用了“观察-思考-工具调用”三步决策机制,具备卓越的泛化能力,资源占用低,可高效运行...
TrendPublish是一个基于人工智能的趋势发现及内容发布平台。它通过多渠道数据采集,从Twitter/X、各类网站等来源获取信息,并利用DeepseekAI、千问等先进 AI 服务进行智能化总结、提取关键信息和生成吸引人的标题。这一系统支持将内容自动发布到微信公众号,同时提供自定义模板和定时发...
智元机器人推出了一款名为AgiBot Digital World的机器人仿真框架,旨在支持机器人操作技能的研究与应用。这一框架结合了大量真实的三维资产、多样化的专家轨迹生成机制以及全面的模型评估工具,通过高度逼真的模拟和全链路的自动化数据生成,能够快速构建多样化的机器人训练场景。 AgiBot Di...