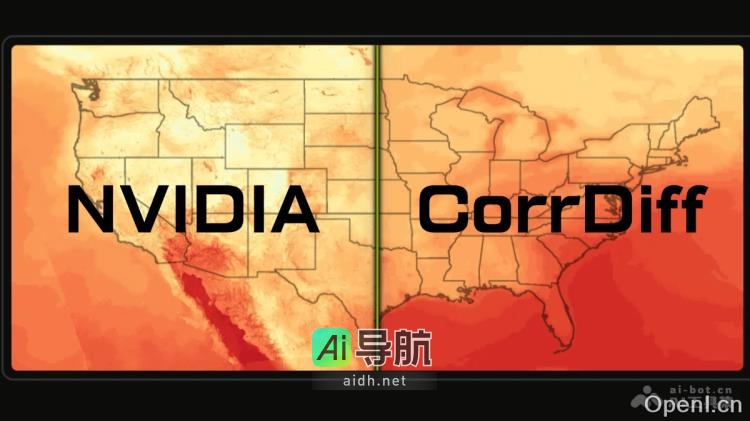
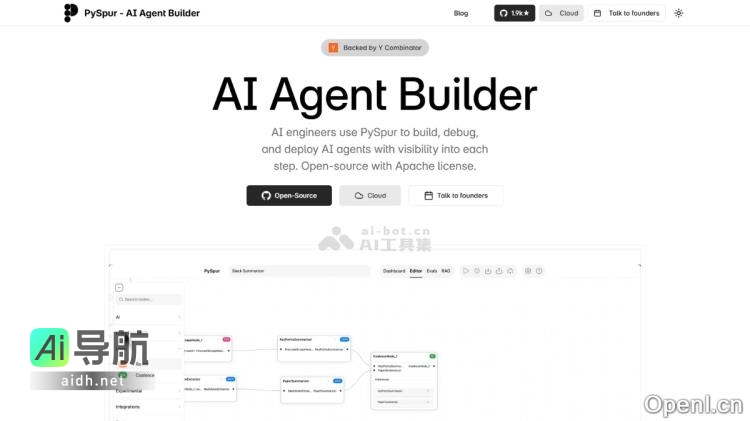
LCVD是四川大学推出的一款名为“光照可控视频扩散模型”(Lighting Controllable Video Diffusion Model)的肖像动画生成框架。该框架能够高保真地生成具有可控光照效果的肖像动画,通过将肖像的内在特征(如身份和外观)与外在特征(如姿态和光照)进行分离,并使用参考适...
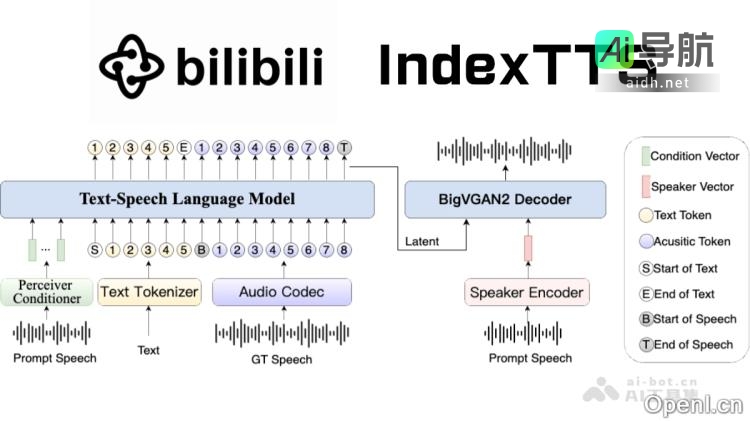
"story-flicks" 是一款 AI 视频生成工具,可通过一键操作生成高清故事短视频。用户只需输入故事主题,系统将应用先进的 AI 技术,自动生成包含图像、文本、音频和字幕的短视频。该项目支持多种模型提供商,如 OpenAI 和阿里云,用户可以根据需求选择不同的文本和图像生成模型。视频时长可根...
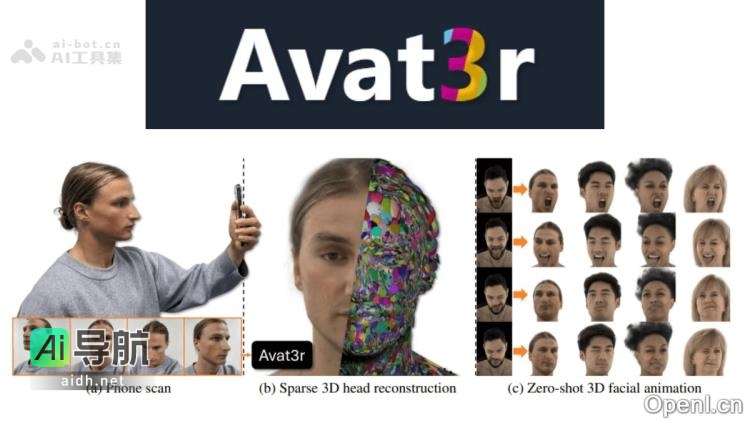
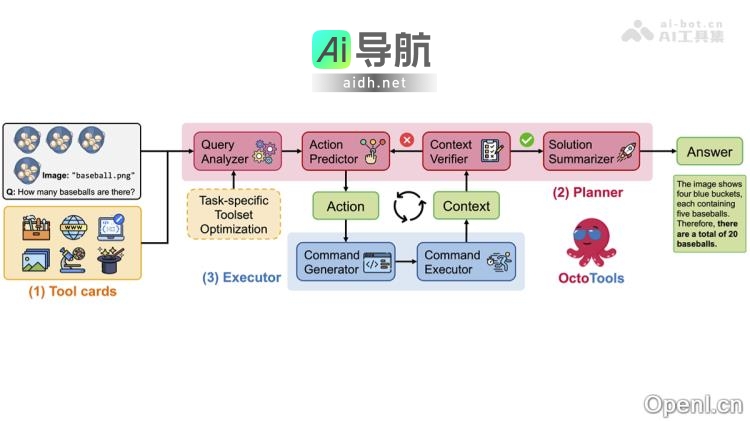
Avat3r 是由慕尼黑工业大学与 Meta Reality Labs 联合开发的一款高保真三维头像重建模型,能够在仅需几张输入图像的情况下,生成高质量且具备动画效果的 3D 头部头像,显著降低了计算资源的需求。该模型通过大规模多角度视频数据集的学习,掌握了强大的三维人头先验知识,并结合 DUSt3...
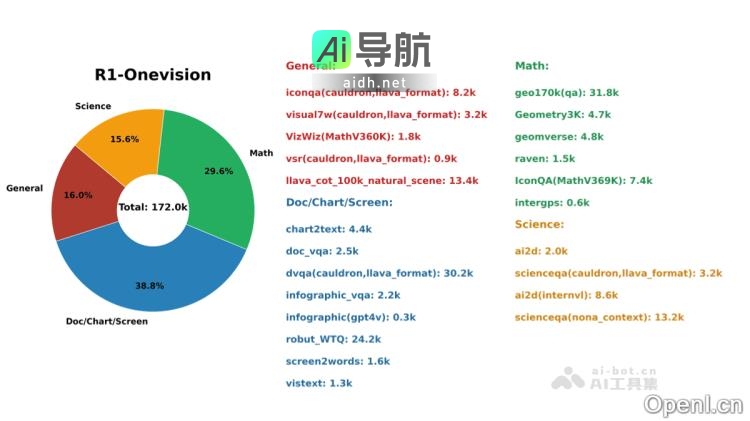
VLM-R1是浙江大学Om AI Lab推出的一款视觉语言模型,采用强化学习技术。该模型可以根据自然语言指令精确定位图像中的目标物体,例如根据描述"图中红色的杯子"找到对应图像区域。VLM-R1建立在Qwen2.5-VL架构基础上,结合了DeepSeek的R1方法,通过强化学习优化与监督微调(SFT...