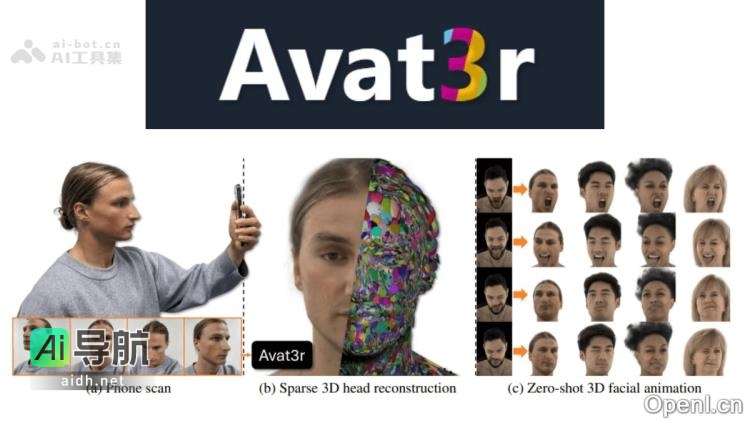
Avat3r 是由慕尼黑工业大学与 Meta Reality Labs 联合开发的一款高保真三维头像重建模型,能够在仅需几张输入图像的情况下,生成高质量且具备动画效果的 3D 头部头像,显著降低了计算资源的需求。该模型通过大规模多角度视频数据集的学习,掌握了强大的三维人头先验知识,并结合 DUSt3R 提供的位置图与 Sapiens 的特征图,从而优化了重建效果。Avat3r 的一大创新在于利用简单的交叉注意力机制实现表情动画,能够从不一致的输入(如手机拍摄或单目视频帧)中重建三维头部头像。
Avat3r的主要功能包括高效生成、动画化能力、鲁棒性和多源输入支持。通过高斯重建技术、多视图数据学习、动画化技术、结合先验模型等技术原理,Avat3r 在少输入和单输入场景中表现卓越,能够在几分钟内从几张输入图像生成高质量的3D头像。此外,Avat3r的应用场景涵盖虚拟现实(VR)、增强现实(AR)、影视制作、视觉特效、游戏开发、数字人及虚拟助手等领域。
更多详细信息,请访问Avat3r的官方网站[https://tobias-kirschstein.github.io/avat3r/]及相关技术论文[https://arxiv.org/pdf/2502.20220]。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点
没有相关内容!

暂无评论...