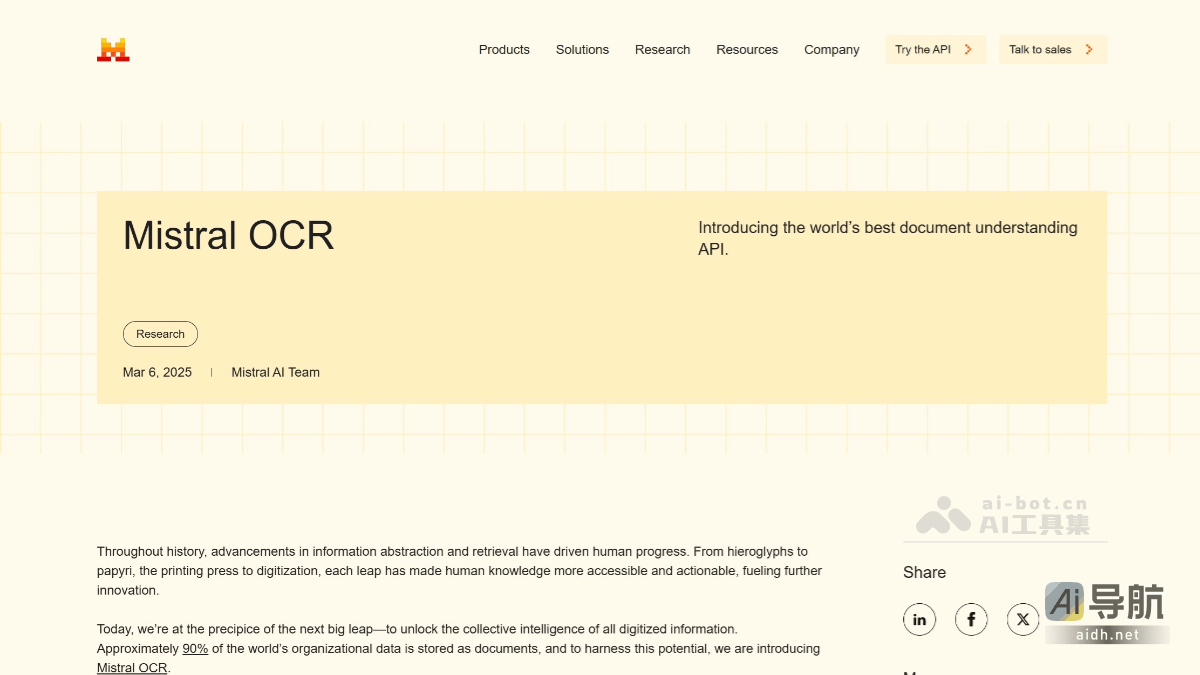
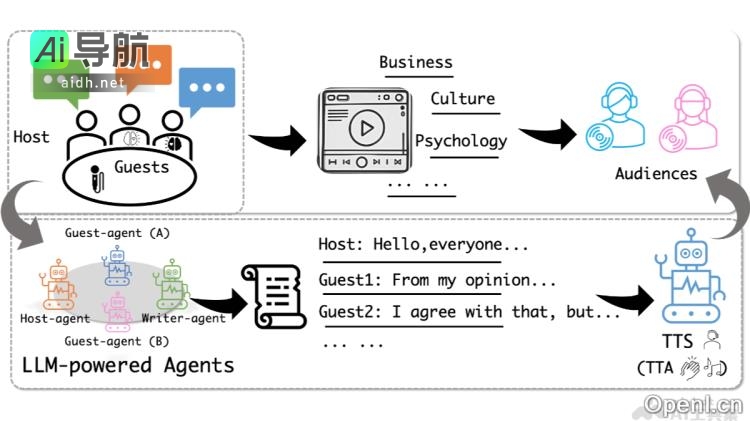
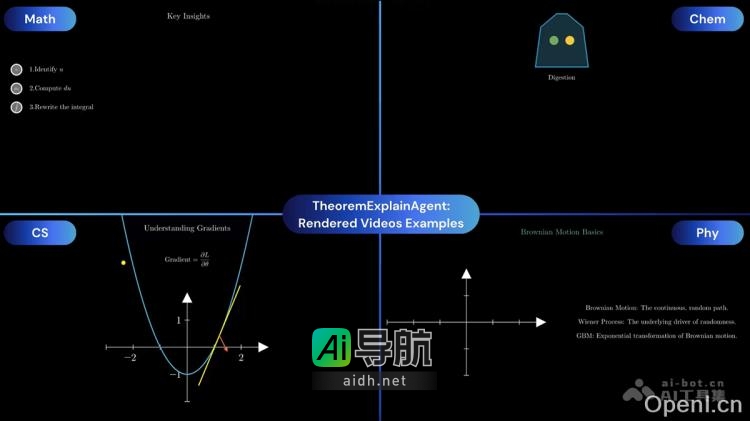
Mistral OCR 是 Mistral AI 最新推出的一款光学字符识别(OCR)工具,专为处理复杂文档而设计。该工具能够全面解析文档中的文本、图像、表格和数学公式,支持多种语言和字体,准确率高达99.02%。在各项基准测试中,Mistral OCR 的表现超越了 Google Document...
微软Dragon Copilot是专为医疗行业设计的人工智能语音助手,旨在协助临床医生简化文档处理、信息检索和任务自动化。结合了Dragon Medical One的先进语音识别技术和DAX Copilot的环境感知AI功能,该产品支持多语言的语音笔记生成、自动化工作流程、个性化文档格式设置以及高效...
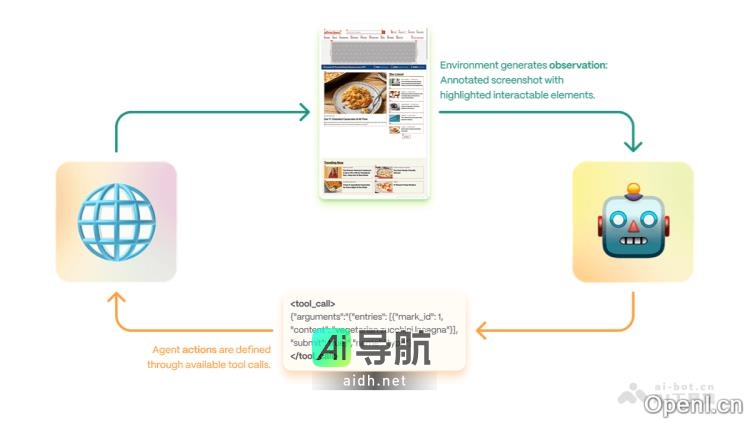
Proxy Lite 是一款开源的轻量级视觉语言模型(VLM),其参数数量为 3B,专注于自动化网页操作。该模型能够像人类一样执行浏览器操作,包括网页交互、数据抓取和表单填写等重复性任务,从而显著降低自动化成本。它采用了“观察-思考-工具调用”三步决策机制,具备卓越的泛化能力,资源占用低,可高效运行...
WiseMind AI 是一款基于人工智能技术的智能学习助手,致力于提供高效的学习和知识管理体验。该平台支持多种文档格式,包括网页、PDF、Markdown等,能够迅速提取文档的核心内容,生成摘要、思维导图和智能笔记。通过将复杂信息转化为易于理解的知识卡片,WiseMind AI帮助用户更好地掌握和...
TrendPublish是一个基于人工智能的趋势发现及内容发布平台。它通过多渠道数据采集,从Twitter/X、各类网站等来源获取信息,并利用DeepseekAI、千问等先进 AI 服务进行智能化总结、提取关键信息和生成吸引人的标题。这一系统支持将内容自动发布到微信公众号,同时提供自定义模板和定时发...