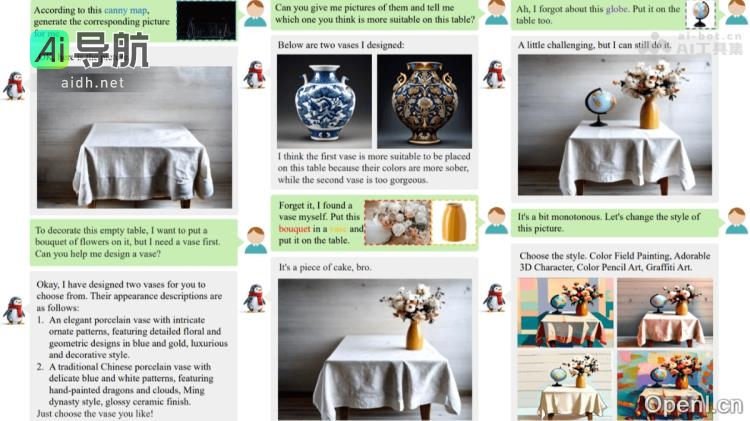
WeGen是由中国科学技术大合作上海交通大学、微信团队及中国科学院等多家机构共同研发的一个综合性多模态生成模型。该模型结合了多模态大语言模型(MLLM)与扩散模型,旨在通过自然对话实现丰富的视觉生成任务。用户可以通过WeGen进行文本到图像生成、条件生成、图像编辑、风格迁移等多种类型任务,并获得多样化的创意输出。WeGen利用动态实例一致性(DIIC)数据管道与提示自重写(PSR)机制解决了实例身份一致性与生成多样性的挑战,展现出作为设计助手的潜力。
WeGen的主要功能包括:
- 文本到图像生成:根据用户的文本描述生成高质量图像
- 条件驱动生成:根据特定条件进行图像生成
- 图像编辑与修复:对图像进行修改、修复或扩展
- 风格迁移:将图像的艺术风格应用到另一图像上
- 多主体生成:在生成的图像中保留多个对象的特征
- 交互式生成:通过自然对话与用户互动逐步优化生成结果
- 创意设计辅助:提供多样的生成选项激发创意灵感
WeGen的技术原理包括多模态大语言模型与扩散模型结合、动态实例一致性、提示自重写、统一框架与交互式生成以及大规模数据集支持。用户可以通过 GitHub 仓库和 arXiv 技术论文获取 WeGen 项目地址。
WeGen的应用场景包括创意设计、内容创作、教育辅助、个性化定制以及虚拟社交与娱乐等领域。用户可以利用 WeGen 快速生成创意概念图,加速创作流程,提供教学辅助等服务。
关于常见问题,WeGen支持多种语言的文本输入,可处理多语种的自然对话。用户可以通过访问 GitHub 仓库获取 WeGen,并了解相关文档。WeGen生成的图像质量高,商业使用可能需要遵循许可证。用户可以在 GitHub 仓库提交问题或建议,与开发者互动。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点





暂无评论...