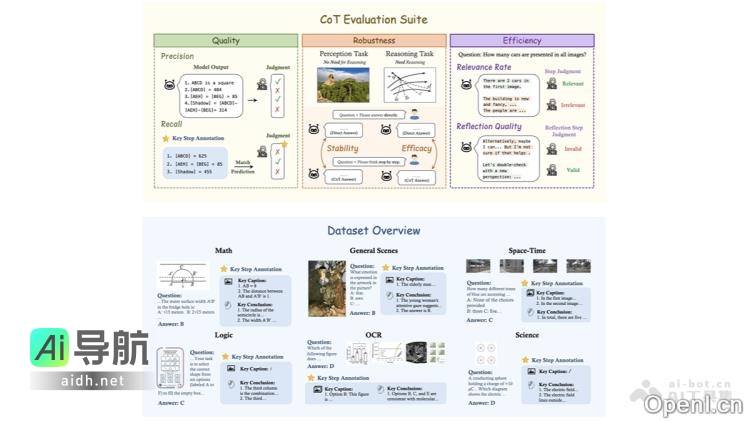
MME-CoT是一项由香港中文大学(深圳)、香港中文大学、字节跳动、学、上海人工智能实验室、宾夕法尼亚大学及清华大学等多家机构共同开发的基准测试框架,旨在评估大型多模态模型(LMMs)在链式思维(CoT)推理能力方面的表现。该框架覆盖了数学、科学、OCR、逻辑、时空和一般场景等六大领域,内含1,130个问题,每个问题配有关键推理步骤和参考图像描述。MME-CoT基准通过推理质量、鲁棒性和效率这三个创新评估指标全面评估模型的推理能力,揭示了当前多模态模型在CoT推理中存在的一些重要挑战,例如反思机制的低效性和感知任务的干扰。
该框架主要功能包括:
- 多领域推理能力评估:包括数学、科学、OCR、逻辑、时空和一般场景六个领域,全面分析模型在不同情境下的推理能力。
- 细致的推理质量评估:利用标注的关键推理步骤和参考图像描述,评估模型推理的逻辑合理性、鲁棒性以及效率。
- 揭示模型推理中的问题:识别多模态模型在CoT推理中遇到的困难,如反思机制的低效性及其对感知任务的负面影响。
- 为模型优化提供指导:评估结果与分析为多模态模型的设计与优化提供了重要的参考,帮助研究人员提升模型的推理能力。
该框架的应用场景包括模型评估与比较、模型优化、多模态研究、教育与培训以及行业应用等领域。若您对MME-CoT有任何疑问或需进一步了解,请访问我们的官方网站或GitHub仓库获取更多信息和支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点





暂无评论...