
人工智能工程联盟 MLCommons 于当地时间 1 月 30 日宣布推出 Unsupervised People’s Speech 数据集。该数据集包含超过 100 万小时的音频内容,**预示着人工智能在音频领域发展的新契机**。

Unsupervised People’s Speech 数据集资源来源于 Archive.org,由 MLCommons 与 HuggingFace 联合创建,且未经任何数据推断和预处理。
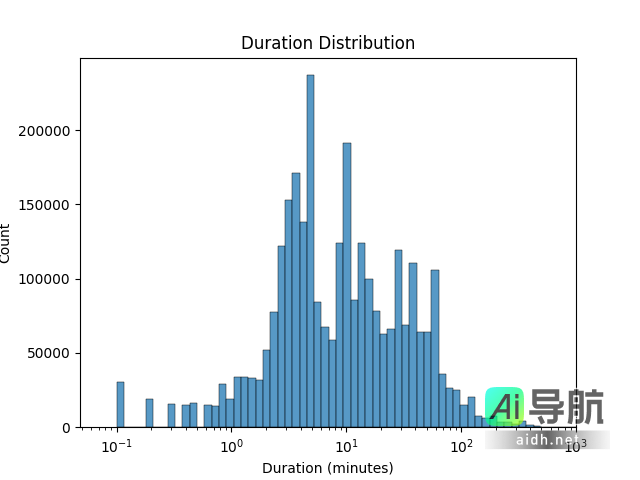
该数据集**总体规模超过 48TB**。尽管 Unsupervised People’s Speech 的内容以美式英语为主,但亦涵盖数十种语言;其中,多数音频时长介于 1 至 10 分钟之间,仅有 14 个音频超过 100 小时。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点








暂无评论...