
引言
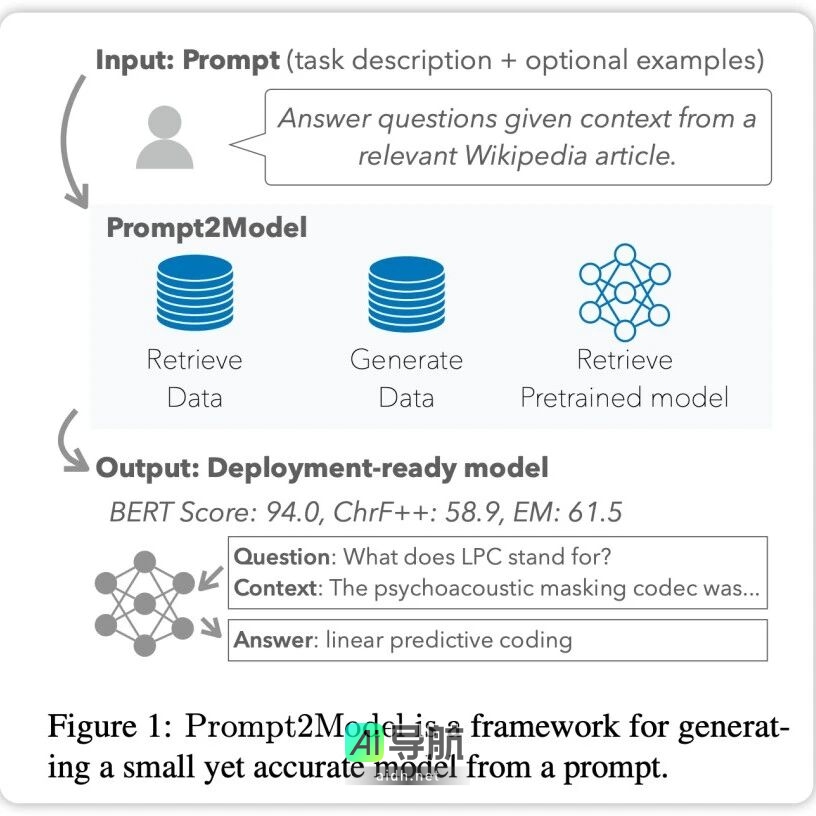
近年来,大规模语言模型(LLM)在自然语言处理(NLP)领域取得了显著进展,但其在特定任务上的应用仍面临高计算成本和隐私问题等挑战。为了应对这些挑战,卡内基梅隆大学(CMU)与清华大学的研究者联合开发了一个名为 Prompt2Model 的框架,旨在通过用户提供的提示快速训练出高效的小型专业模型。
Prompt2Model 框架概述
框架目的与优势
Prompt2Model 框架的核心目标是简化特定任务模型的构建过程。用户只需提供简单的自然语言提示,框架便能够自动收集所需数据并训练出适用的模型。该框架的优势在于:
- 成本低廉:仅需 5 美元用于数据收集。
- 快速训练:模型训练时间大约为 20 分钟。
- 性能优越:生成的模型在多个任务上表现超越了 GPT-3.5-turbo 模型,性能提升可达 20%。
- 参数规模小:新模型的参数规模相比于大型模型缩小了约 700 倍。
自动化流程
Prompt2Model 的工作流程是高度自动化的,主要包括以下几个步骤:
- 数据集与模型检索:自动收集相关数据集和预训练模型。
- 数据集生成:利用 LLM 创建伪标记数据集。
- 模型微调:通过混合检索数据和生成数据对模型进行微调。
- 模型测试:在测试数据集和用户提供的真实数据集上对模型进行测试。
通过这些步骤,Prompt2Model 能够高效地构建自然语言处理系统,显著降低开发成本。
实验与验证
实验设计
研究团队在三个自然语言处理子任务上进行了实验,以评估 Prompt2Model 的性能:
- 机器阅读问答:使用 SQuAD 数据集进行评估。
- 日语自然语言到代码转换:使用 MCoNaLa 数据集进行评估。
- 时间表达式规范化:使用 Temporal 数据集进行评估。
实验结果
实验结果显示,Prompt2Model 在多个任务上均优于基准模型 GPT-3.5-turbo,尽管生成的模型参数规模远小于后者。具体结果如下:
- 在机器阅读问答和时间表达式规范化任务中,Prompt2Model 生成的模型表现显著优于 GPT-3.5-turbo。
- 在日语到代码转换任务中,Prompt2Model 的表现不如 GPT-3.5-turbo,可能是由于生成的数据集质量不高以及缺乏适当的预训练模型。
- 数据生成器所生成的测试数据集能够有效区分不同模型在实际数据集上的性能,说明生成的数据质量较高。
这些结果表明,Prompt2Model 在多个任务上成功生成了高质量的小型模型,极大地减少了对人工标注数据的需求。
结论与展望
Prompt2Model 框架的推出为构建特定自然语言处理模型提供了一种低成本、易于上手的解决方案,极大地降低了技术门槛。研究结果表明,使用该框架生成的模型在多个任务上表现优越,且能够有效评估模型的真实性能。
未来,研究团队计划继续优化框架的性能,提升生成数据的质量,以进一步扩展其应用范围。这一框架的成功开发不仅有助于推动 NLP 技术的广泛应用,也为行业用户提供了更多的选择和便利。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点





暂无评论...