TOMG-Bench:全新基准用于评估大语言模型在开放域分子生成中的表现 科学家们提出了一种新型的基准测试——TOMG-Bench,旨在评估大型语言模型(LLM)在分子领域的开放域生成能力。 项目主页:https://phenixace.github.io/tomgbench/ 数据集与测试脚本:https://github.com/phenixace/TOMG-Benc... +3 智能之星10个月前
探讨AI时代下管理变革的稀土掘金创新论坛 2023年,我们目睹了人工智能带来的产业变革以及对业务的直接影响,不管是FOMO(害怕错过)还是JOMO(享受错过),技术决策者都面临着新技术带来的直接挑战。在这个背景下,首届「稀土掘金创新论坛」将于2023年10月28日在北京·新云南皇冠假日酒店举行,这是由稀土掘金技术社区主办的面向技术决策者的高... AGI2年前
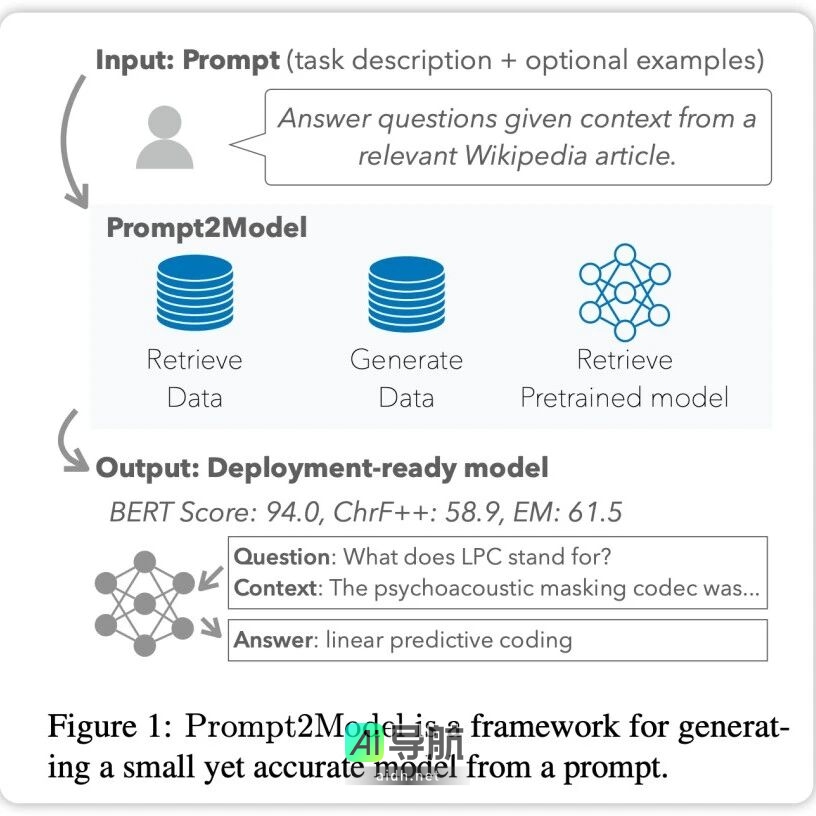
通过1句指令、5美元和20分钟,轻松训练出小型专业模型,快来了解Prompt2Model! 引言 近年来,大规模语言模型(LLM)在自然语言处理(NLP)领域取得了显著进展,但其在特定任务上的应用仍面临高计算成本和隐私问题等挑战。为了应对这些挑战,卡内基梅隆大学(CMU)与清华大学的研究者联合开发了一个名为 Prompt2Model 的框架,旨在通过用户提供的提示快速训练出高效的小型专业模... 开放I2年前
AI:探讨大模型领域最新算法SOTA进展 GPT-4的智能思维逐渐向人类靠拢。人类在犯错时会进行自我反思,以避免再次犯错。如果GPT-4等大型语言模型也具备这种反思能力,其性能将会大幅提升。 众所周知,大型语言模型(LLM)在各种任务上已取得了前所未有的性能。然而,这些最先进技术(SOTA方法)通常需要微调模型、优化策略等操作,来适应已定义... AGI3年前