

科学家们提出了一种新型的基准测试——TOMG-Bench,旨在评估大型语言模型(LLM)在分子领域的开放域生成能力。

项目主页:https://phenixace.github.io/tomgbench/
数据集与测试脚本:https://github.com/phenixace/TOMG-Bench
预印本:https://arxiv.org/abs/2412.14642
Huggingface 数据集:https://huggingface.co/datasets/Duke-de-Artois/TOMG-Bench
PaperWithCode:https://paperswithcode.com/dataset/tomg-bench
分子发现是推动医药与材料科学等领域进步的关键环节。然而,传统的分子发现方法常常依赖反复实验和数据分析,这不仅效率低下,还需付出高昂的成本。
伴随机器学习技术的飞速发展,图神经网络(GNN)等人工智能工具在分子发现领域展现出巨大潜力。然而,GNN方法也存在一定局限性,如泛化能力不足以及在生成特定性质分子结构方面的不足。
大型语言模型(LLM)凭借其卓越的语言理解、生成能力和泛化能力,为分子发现领域开辟了新的机遇。LLM可以将分子结构文本化,从而理解分子的结构特征,并能够生成全新的分子结构。
然而,将分子与文本数据进行有效的对齐仍然是一项挑战。先前的分子—描述文本数据集,如ChEBI-20和PubChem,主要基于给定的描述生成唯一对应的分子(即文本导向的目标预设分子生成)。而在实际情况下,化学家设计分子的需求常常较为模糊,可以对应多个符合要求的分子,如图1所示。这使得开发新的数据集和基准测试至关重要,以便更好地评估LLM在分子发现中的性能。
为应对上述挑战,来自香港理工大学、上海交通大学及上海人工智能实验室的研究人员共同开发了基于文本的开放分子生成基准测试(TOMG-Bench),其目的在于评估LLM在分子领域的开放域生成能力。
TOMG-Bench包含三个主要任务:分子编辑、分子优化与定制分子生成,涵盖分子发现过程中的多个关键环节。通过TOMG-Bench,我们将能更深入地了解LLM在分子发现中的优势与局限,从而推动其在该领域的应用。
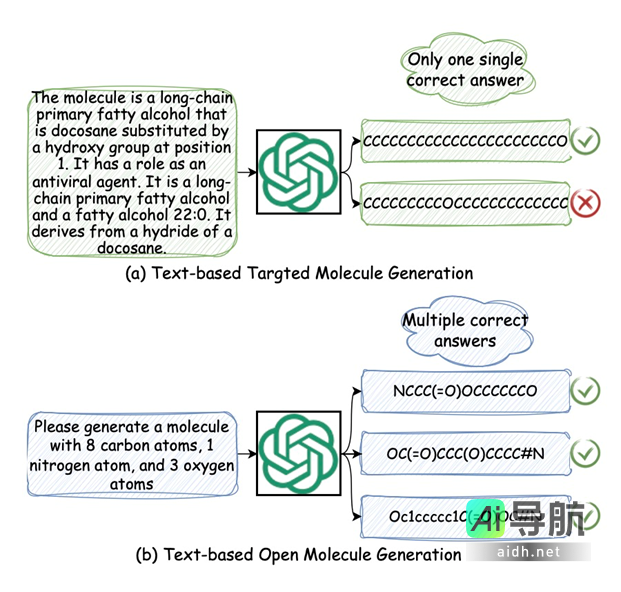
图1:对比基于文本的目标导向分子生成 (a) 与开放式分子生成 (b)
现有分子-文本对齐所面临的挑战
1. 数据集及基准测试的欠缺:目前现存的数据集,例如ChEBI-20和PubChem,均依赖于分子-描述对,这些数据集在满足开放域分子生成任务的需求方面显得不足。这些数据集通常是在特定描述下生成唯一对应的分子,而化学家在实际设计分子时需求常常是模糊的,能够对应多个适合的分子。
2. 分子-描述翻译任务的局限性:分子-描述翻译任务是跨越分子空间和自然语言空间的桥梁,然而存在显著的局限。一方面,在实际应用中,分子描述可能高度模糊,具有多种可接受的解释,而现有的分子-描述翻译实际上只是目标生成任务,模型难以有效泛化至用户的特定需求。
3. 新分子结构生成能力不足:当前分子-描述翻译任务及其相关评估指标无法有效评估LLM生成新型分子结构的能力,而这一点对于分子发现,尤其是在药物发现领域而言至关重要。
TOMG-Bench
TOMG-Bench是一个创新的基准测试,旨在对LLM在分子领域的开放域生成能力进行全面评估。与传统基于文本的目标导向分子生成任务不同,TOMG-Bench的任务实现了开放域生成,不再设定特定的目标分子,而是让LLM生成满足特定要求的多样性分子结构。这种开放性更贴近化学家在实际工作中所面临的需求,更能体现LLM的泛化能力与创造性。该基准包含三个主要任务,每个任务细化为三个子任务,涵盖了分子发现的多个重要环节:
1. 分子编辑(MolEdit)
添加组件 (AddComponent):指令LLM向给定分子添加特定的官能团。
删除组件 (DelComponent):指令LLM从给定分子中删除特定的官能团。
替换组件 (SubComponent):指令LLM从给定分子中删除特定的官能团,并添加新的官能团。
2. 分子优化(MolOpt)
优化 LogP 值 (LogP):指令LLM优化分子结构,使其LogP值降低或升高。
优化 MR 值 (MR):指令LLM优化分子结构,使其MR值降低或升高。
优化 QED 值 (QED):指令LLM优化分子结构,使其QED值降低或升高。
3. 定制分子生成(MolCustom)
指定原子数量(AtomNum):指令LLM生成指定数量和类型的原子组成的分子。
2: TOMG-Bench 中任务的示例。右侧的分子被认为是有效的生成结果。
数据生成
TOMG-Bench 的测试用例主要针对 MolEdit 和 MolOpt 两类任务进行生成,而 MolCustom 任务的测试用例则根据实际需求随机生成。
1. MolEdit 和 MolOpt 任务:
数据来源:从 Zinc250K 数据库中随机选取分子作为测试样本。
分子统计:利用 RDKit 工具箱收集分子的基本统计信息,包括分子结构模式及其化学性质(如 LogP、MR、QED 值等)。
任务提示:将收集的分子统计数据整合至预先定义的任务提示中,具体示例如下:
MolEdit 任务示例:如表所示,例如:“请将分子 c1ccccc1O 中的羟基替换为羧基。”

MolOpt 任务示例:如表所示,例如:“请优化分子 c1ccccc1O,使其 LogP 值降低。”

2. MolCustom 任务:
数据来源:随机生成符合特定要求的分子指令,例如:
AtomNum 子任务示例:「请生成一个含有 6 个碳原子和 1 个氧原子的分子。」
BondNum 子任务示例:「请生成一个含有 10 个键的分子。」
FunctionalGroup 子任务示例:「请生成一个含有苯环和羧基的分子。」
任务提示:如表所示:

评估指标
1. MolEdit 和 MolOpt 任务:
成功率 (Success Rate): 通过化学工具箱(如 RDKit)自动检查生成的分子是否满足预设要求。例如,对于 MolEdit 任务中的 AddComponent 子任务,将检查生成分子中是否包含指定数量的的目标官能团;对于 MolOpt 中的 LogP 子任务,将核实生成分子的 LogP 值是否符合优化要求。
相似性 (Similarity): 评估生成分子与原始分子之间的相似程度。利用 Tanimoto 相似度算法,将分子转换为 Morgan 指纹,并比较指纹之间的交集和并集。
有效性 (Validity): 评估生成分子的化学有效性,即是否符合分子结构的规范。
2. MolCustom 任务:
成功率 (Success Rate): 通过化学工具箱自动检测生成分子是否满足给定的原子数量、键数量或官能团要求。
新颖性 (Novelty): 评估生成分子与现有分子之间的差异。以 Zinc250K 数据库作为参考,计算生成分子与现有分子的平均 Tanimoto 相似度,并以此作为新颖性评分。
有效性 (Validity): 与 MolEdit 和 MolOpt 任务采用相同的评估标准,检查生成分子的化学有效性。
3. 平均加权成功率 (Average Weighted Success Rate):
由于仅凭成功率无法充分反映分子编辑与优化的过程(即生成的分子是基于指定分子编辑的结果还是全新生成的),同时新颖性也是评估定制分子生成的重要指标,因此引入平均加权成功率这一综合评估指标。此指标将相似性评分和新颖性评分作为成功率的权重,以平衡评估结果。
OpenMolIns 指令微调数据集
OpenMolIns 是为 TOMG-Bench 专门开发的指令微调数据集,旨在提升 LLM 在开放域分子生成任务中的理解与执行能力。
1. 数据来源:
OpenMolIns 的数据来源于 PubChem 数据库,而非 Zinc250K 数据库,以确保避免数据泄漏。在 OpenMolIns 数据集中的分子与 Zinc250K 数据库的分子实现互不重叠。
2. 数据结构:
OpenMolIns 数据集按照五种不同的数据规模进行构建:
轻 (Light): 包含 4,500 个样本。
小 (Small): 包含 18,000 个样本。
中 (Medium): 包含 45,000 个样本。
大 (Large): 包含 90,000 个样本。
超大 (Xlarge): 包含 1,200,000 个样本。
在每个数据规模中,九个子任务的样本数量均匀分布。
3. 数据内容:
OpenMolIns 数据集包含九个子任务的指令与对应的目标分子结构:
AddComponent, DelComponent, SubComponent (MolEdit): 指令 LLM 对分子进行添加、删除或替换官能团的操作。
LogP, MR, QED (MolOpt): 指令 LLM 优化分子的 LogP、MR 或 QED 值。
AtomNum, BondNum, FunctionalGroup (MolCustom): 指令 LLM 生成指定原子数量、键数量或官能团的分子。
每个样本均包含一条指令及其对应的目标分子结构,旨在指导 LLM 的训练和微调。
4. 数据格式:
OpenMolIns 数据集采用 SMILES 字符串表示分子结构,指令则采用自然语言文本形式,描述对分子的具体操作或要求。
Claude-3.5 和 Gemini-1.5-pro),它们在 MolCustom 任务上的成功率依然低于 25%,这表明 LLM 在从零开始生成分子结构方面仍面临重大挑战。
2. **开源模型的迅速追赶**:在 TOMG-Bench 的评测中,开源模型 Llama-3.1-8B-Instruct 的平均加权成功率超越了所有开源通用 LLM,甚至超过了 GPT-3.5-turbo。这一结果表明,即使未经过化学相关语料库的预训练,开源模型依然展现出强大的分子理解与生成能力。
3. **模型能力与性能的正相关性**:实验结果表明,模型的能力与其在 TOMG-Bench 上的表现呈现正相关例。例如,Llama-3.1-8B-Instruct 的性能优于 Llama-3.2-1B-Instruct,而 Llama-3.70B-Instruct 的表现又优于 Llama-3.1-8B-Instruct,指出更大的模型通常能够生成更高质量的分子结构。
4. **ChEBI-20 数据集在分子-文本对齐训练中的不足**:虽然 ChEBI-20 数据集在分子到描述的翻译任务中表现出色,但基于该数据集微调的 LLM 在 TOMG-Bench 上的性能却不尽如人意,暗示 ChEBI-20 缺乏足够的多样性,从而难以使 LLM 熟悉分子结构的复杂性和多样性。
5. **数据规模对性能的重要性**:实验结果显示,数据规模显著影响 LLM 在 TOMG-Bench 上的表现。例如,Galactica-125M 在 OpenMolIns-xlarge 数据集上的表现优于 Llama3-70B-Instruct,表明更大的数据集有助于进一步提升 LLM 的性能。
6. **TOMG-Bench 反映了 LLM 的领域泛化能力**:尽管现有的 LLM 在某些基准(如数学)中表现出色,它们仍可能是“偏科生”,难以将能力泛化到预训练中未涉及的任务上。这种“偏科”现象可能会影响用户使用 LLM 的实际体验。因此,TOMG-Bench 在某些情况下能够帮助识别现有模型的缺陷,并为模型改进提供思路。
Leaderboard
在 TOMG-Bench 的模型排名中,前五名如下:
– Claude-3.5:平均成功率为 51.10%,加权成功率为 35.92%。
– Gemini-1.5-pro:平均成功率为 52.25%,加权成功率为 34.80%。
– GPT-4-turbo:平均成功率为 50.74%,加权成功率为 34.23%。
– GPT-4o:平均成功率为 49.08%,加权成功率为 32.29%。
– Claude-3:平均成功率为 46.14%,加权成功率为 30.47%。
Llama-3.1-8B(OpenMolIns-large)排名第六,平均成功率为 43.1%,加权成功率为 27.22%。这一表现表明 OpenMolIns 数据集对提升 LLM 在分子生成任务中的性能具有显著效果。
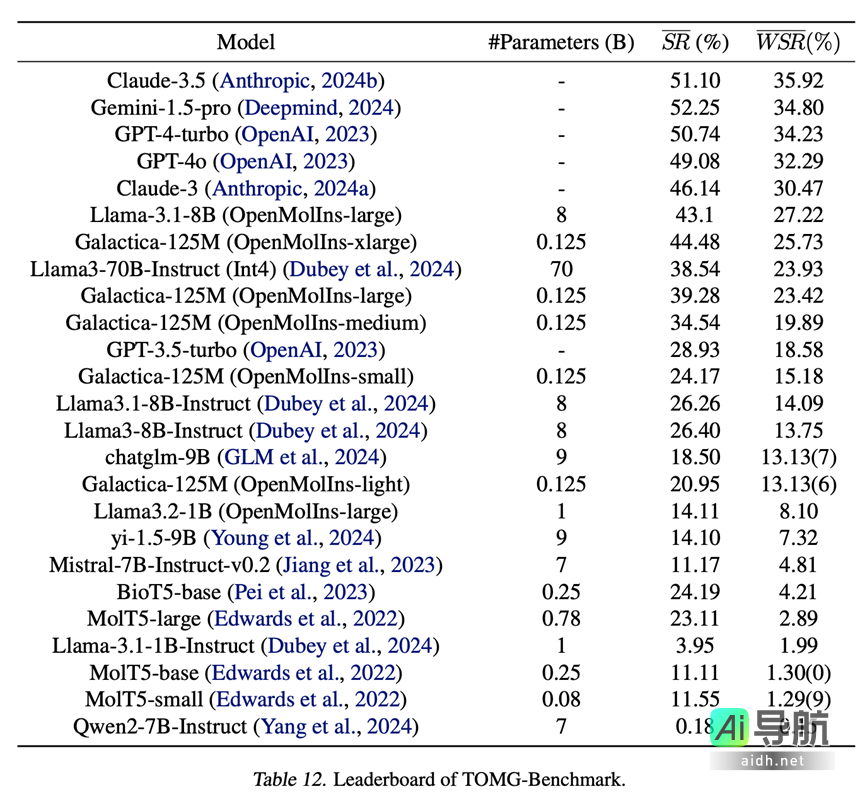
图 3: TOMG-Bench 的排行榜
总结
TOMG-Bench 是首个用于评估大型语言模型(LLM)在开放域分子生成能力方面的基准测试。该基准包括一个数据集,涵盖三个主要任务:分子编辑(MolEdit)、分子优化(MolOpt)和定制分子生成(MolCustom)。每一任务又包含三个子任务,各自拥有 5,000 个测试样本。鉴于开放域分子生成的复杂性,系统将采用自动化评估方式来评估 LLM 生成分子的质量。
对 25 个 LLM 的综合基准测试揭示了在文本引导的分子发现中目前存在的局限性及潜在改进方向。此外,借助 OpenMolIns 指令微调数据集的支持,Llama3.1-8B 能够在 TOMG-Bench 上的表现超越所有开源通用 LLM,甚至比 GPT-3.5-turbo 高出 46.5%。
该测试脚本与数据集也已完成开源,欢迎大家积极尝试 TOMG-Bench,同时期待更多用户参与其中!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点


暂无评论...