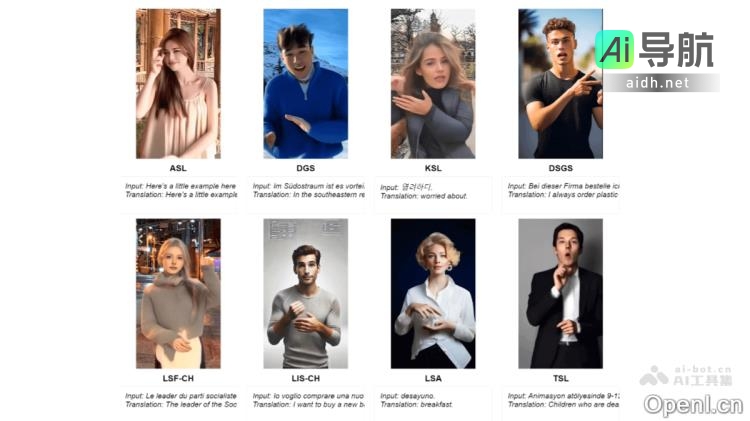
SignLLM是一个多语言手语生成模型,能够将文字输入转化为对应的手语视频。作为全球首个支持多国手语的系统,它包括美国手语(ASL)、德国手语(GSL)、阿根廷手语(LSA)、韩国手语(KSL)等八种语言。该模型基于Prompt2Sign数据集开发,利用先进的自动化技术从网络中获取和处理手语视频,并结合新颖的损失函数和强化学习模块,实现高效的数据提取和模型训练。
SignLLM的主要功能包括:
- 手语视频生成:能够将输入文本流畅地转换为手语手势视频,跨多种语言。
- 多语言支持:覆盖八种手语,服务于不同国家和地区的需求。
- 高效训练与优化:通过强化学习模块加速模型训练,提高数据采样的质量。
- 风格迁移与微调:调整生成的手语视频,使其更逼真,接近真人手语效果。
- 教育与翻译支持:可应用于手语教学、手语翻译,为聋人群体提供沟通帮助。
SignLLM的技术原理包括:
- 离散化与层次化表示:通过向量量化视觉手语(VQ-Sign)模块和码本重建与对齐(CRA)模块实现手语视频的表示。
- 自监督学习与上下文预测:VQ-Sign模块采用上下文预测任务进行自监督学习,捕捉手语视频的时间依赖性和语义关系。
- 符号-文本对齐:引入最大平均差异(MMD)损失函数提高手语标记与文本标记的语义兼容性。
- 与LLM的结合:结合冻结的LLM生成手语句子,实现高效的手语到文本翻译。
- 训练与推理:分为预训练和微调两个阶段,进一步优化模型性能。
SignLLM在教育领域、医疗场景、法律与公共服务、娱乐与媒体以及日常生活等多个领域具有广泛的应用前景。项目相关信息可在以下地址获取:
- 项目官网:https://signllm.github.io/
- Github仓库:https://github.com/SignLLM
- arXiv技术论文:https://arxiv.org/pdf/2405.10718
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点





暂无评论...