在国际可重构计算领域的顶级会议FPGA 2025闭幕之际,传来喜讯:最佳论文奖项授予了无问芯穹及上海交通大学与清华大学合作提出的“视频生成大模型推理IP工作FlightVGM”。值得一提的是,这是FPGA会议首次将该奖项颁给完全由中国大陆科研团队主导的研究成果,同时也标志着亚太国家团队首次获此殊荣。

FlightVGM首次在FPGA平台上实现了视频生成模型(Video Generation Models, VGMs)的高效推理。该项研究继承了该团队在FPGA’24会议上实现大语言模型FlightLLM加速的成功,展现了其在视频生成领域的最新进展。与NVIDIA 3090 GPU相比,FlightVGM在AMD V80 FPGA上实现了1.30倍的性能提升及4.49倍的能效提升(峰值算力差距超过21倍)。
 论文链接:https://dl.acm.org/doi/10.1145/3706628.3708864
论文链接:https://dl.acm.org/doi/10.1145/3706628.3708864
该论文的第一作者刘军为上海交通大学的博士生,参与作者曾书霖为清华大学的博士后,通讯作者包括汪玉与戴国浩。汪玉为IEEE Fellow,担任清华大学电子工程系教授及系主任,并是无问芯穹的创始人;戴国浩则为上海交通大学副教授,同时是无问芯穹的联合创始人和首席科学家。
回顾往届,清华大学电子工程系的相关工作首次在FPGA国际会议上被收录可追溯至2016年的“Going Deeper with Embedded FPGA Platform for Convolutional Neural Network”及2017年的“ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA”。前者促成了深鉴科技的创立,而后者在同期被评选为最佳论文,使得深鉴科技于2018年被赛灵思以3亿美元的价格收购。
在当下大模型部署成本备受争议的产业背景下,通过FPGA、ASIC等灵活可编程硬件和专用任务集成电路提升硬件运行效率将可能成为推动大模型应用落地效率与降低成本的关键环节。2024年,无问芯穹的定制推理IP FlightLLM获得FPGA会议的高度认可,而今年更以VGM模型定制推理IP FlightVGM荣膺最佳论文奖,均展示了通过创新硬件架构提升效率的潜力。据悉,这些研究成果已被集成至无问芯穹自研的大模型推理IP LPU(Large-model Processing Unit)中,并正与合作伙伴进行实际应用验证。
接下来将对论文的核心内容进行深入解读。
背景
在视频生成领域,扩散Transformer(DiT)正逐渐成为一种重要框架。DiT模型通过扩散过程生成视频,逐步将噪声图像还原为清晰的视频帧,展现出强大的生成能力。最初提出DiT的目的是探索其在大规模数据处理中的可扩展性,随着技术的发展,该架构不断得到优化,从而提高了生成视频的质量与分辨率,使得生成的视频更加清晰细腻。然而,这种方法在生成高分辨率和较长时长视频时,对计算的需求十分庞大,导致计算量和内存消耗显著增加。因此,提升生成效率与优化计算过程,成为该领域面临的重要挑战之一。
核心见解:从视频压缩到视频生成
视频压缩技术(如H.264、H.265)通过离散余弦变换(DCT)等手段识别并消除视频帧间和帧内的冗余信息,从而实现高达1000倍的压缩率。这一策略的核心在于视频数据在时间与空间维度上存在大量重复模式,比如相邻帧之间的背景相对稳定或同一帧内的纹理具有高度相似性。通过检测并跳过这些冗余信息,压缩算法能够显著减少数据量,同时保持视频质量。
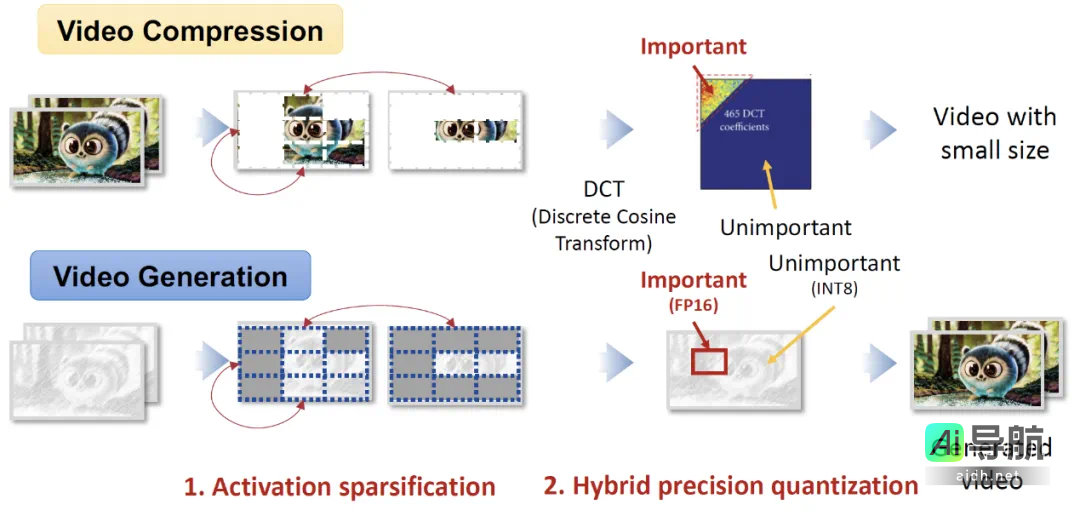
FlightVGM创新性地将这一思想应用于视频生成模型的加速过程中。视频生成模型(VGMs)在推理期间同样表现出显著的时空冗余特性。例如,相邻帧之间的Token在语义上高度相似,而同一帧内的不同区域可能共享相同的视觉特征。然而,当前的GPU架构未能有效利用这种冗余性。虽然FPGA在稀疏计算方面具备优势,但其峰值算力仍低于GPU,并且其传统的计算单元(如V80的DSP58)未能动态适应混合精度需求,这限制了其在视频生成加速中的应用。FlightVGM通过以下三项技术解决了上述挑战:
1. “时间-空间”激活值在线稀疏化方法:基于视频压缩中的相似性检测思想,FlightVGM设计了用于帧间和帧内冗余激活的稀疏机制。通过余弦相似度计算,动态跳过相似部分的计算,从而显著降低计算负载。
2. “浮点-定点”混合精度DSP58拓展架构:借鉴于视频压缩中的分块处理思想,FlightVGM对视频生成模型的不同模块进行精度分层处理。关键模块(如注意力机制)保持FP16精度,而非关键模块(如线性层)则量化为INT8,最大化硬件利用率。
3. “动态-静态”自适应调度策略:针对激活值在线稀疏化引发的负载不均衡问题,FlightVGM能够根据实际工作负载自适应调整不同操作负载的执行顺序,从而提高计算利用率。
将该结果共享给另一个 token。具体而言,输入激活被表示为一个三维张量,该张量是通过 tokenizer 从噪声视频中处理得到的。输入激活可表述为  ,其中 F 代表帧数,T 代表每帧的 token 数量,d 则为隐藏维度。为了简化说明,标记为 (
,其中 F 代表帧数,T 代表每帧的 token 数量,d 则为隐藏维度。为了简化说明,标记为 ( ) 表示第一帧的第一个 token。对于输入激活
) 表示第一帧的第一个 token。对于输入激活  ,我们分别采用
,我们分别采用  和
和  来表示参考向量及输入向量。我们利用余弦相似度作为相似度度量。
来表示参考向量及输入向量。我们利用余弦相似度作为相似度度量。
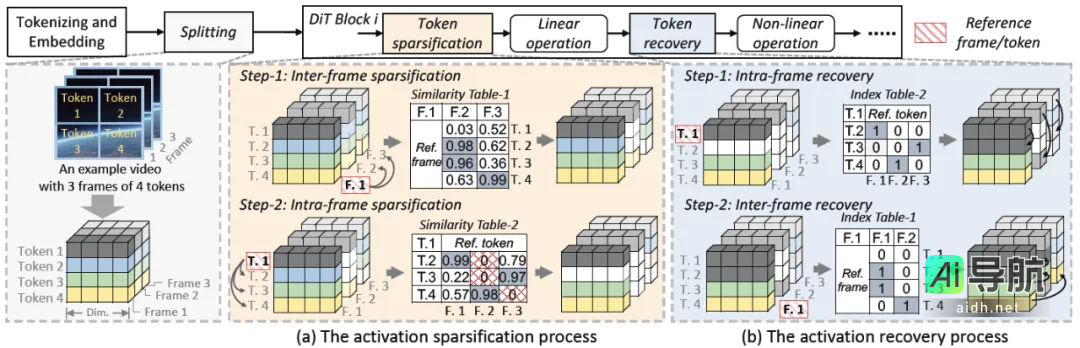
激活稀疏化过程可分为两个步骤:帧间稀疏化与帧内稀疏化。
1. 帧间稀疏化:我们将输入激活划分为 G 个连续组,并选定中间帧作为参考帧。其余帧的 token 将逐一与参考帧的 token 计算相似度,若相似度超过设定的阈值,则用参考帧的 token 计算结果替代当前 token。
2. 帧内稀疏化:对于每一帧中的 token,我们将其分为 K 个块,并以中间 token 作为参考 token,计算其他 token 与参考 token 的相似度。若相似度超过既定阈值,则用参考 token 的值替代计算结果。如果某个 token在帧间稀疏化步骤中已经被剔除,则其相似度为零。
从计算角度来看,相似度的计算需要进行一次内积运算和两次模长计算,因此其计算复杂度为 3d,其中 d 是隐藏维度。以一个线性操作为例,假设输入激活  的维度为
的维度为  ,权重矩阵 W 的维度为
,权重矩阵 W 的维度为  ,则原始操作的计算复杂度为
,则原始操作的计算复杂度为  。在进行稀疏化操作时,考虑到帧间及帧内稀疏化带来的额外计算,假设稀疏度为 s,稀疏操作的总计算复杂度为:
。在进行稀疏化操作时,考虑到帧间及帧内稀疏化带来的额外计算,假设稀疏度为 s,稀疏操作的总计算复杂度为:
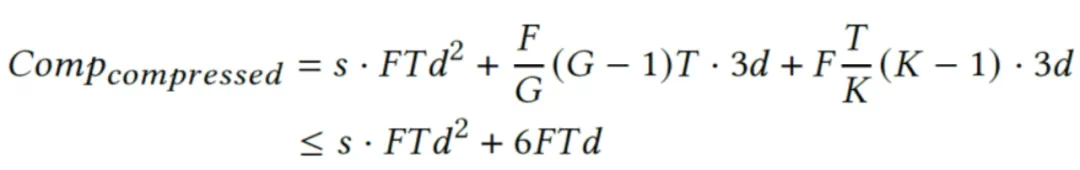
由于原始计算复杂度中包含了 d 的平方项,而稀疏化所引入的额外计算仅为 d 的线性项(通常 d=1152),因此稀疏化带来的额外开销几乎可以忽略不计。
“浮点 – 定点” 混合精度 DSP58 扩展架构
AMD V80 FPGA 配备硬件 IP DSP58,支持多种计算模式,包括标量、向量及浮点配置。然而,这些模式之间无法在运行时动态切换,与视频生成模型对于混合精度的需求存在矛盾,从而未能充分利用 DSP58 的计算潜力。
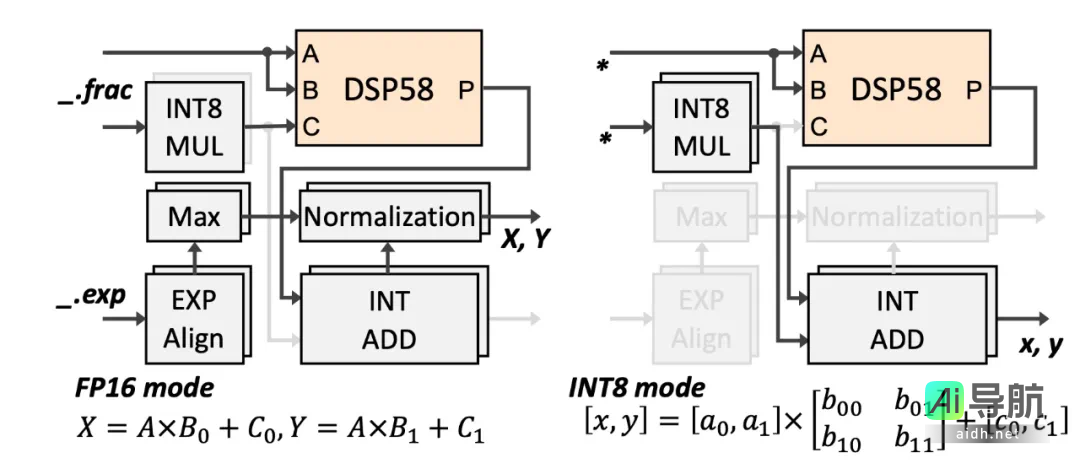
为了解决这一问题,我们提出了一种基于 DSP58 的创新性 FP16-INT8 混合精度硬件架构——DSP-Expansion (DSP-E)。该架构允许在运行时进行配置,能够支持两个 FP16 乘加单元(MAC)或四个 INT8 乘加单元。我们核心的思路是通过引入额外的乘法器,来解决 DSP58 在执行两个 FP16 分数乘法时所产生的数据混淆问题,这些乘法器也可以在 INT8 模式下进行复用。在 FP16 模式下,DSP58 执行两个 MAC 的分数乘法,并通过减去 INT8 乘法器的结果来获得正确的中间计算值。中间结果的指数部分通过整数加法器进行计算,并通过指数对齐和调整单元来对齐小数点位置,最终通过加法、归一化及四舍五入操作得出最终结果。在 INT8 模式下,DSP-E 通过复用 DSP58、两个 INT8 乘法器及两个整数加法器,实现了极大的计算性能提升。通过将相关数据输入到不同的端口,额外的逻辑单元能够有效地重用硬件资源,从而显著提高计算吞吐量。
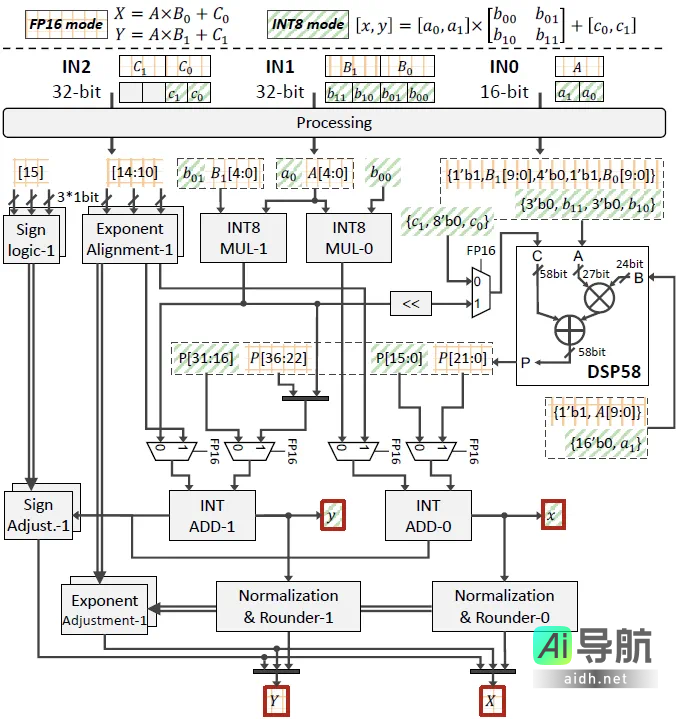
为了在计算精度和硬件资源的约束下实现最大吞吐量,我们设计了一个异构的 DSP58 阵列,以适应不同的计算需求。我们根据不同设计的资源消耗(涵盖 DSP、LUT、REG、RAM 等)进行评估,确保通过资源约束实现最优计算性能。此外,我们还考虑 INT8 与 FP16 计算性能的比值,以评估计算能力的增进。
实验结果
算法评估
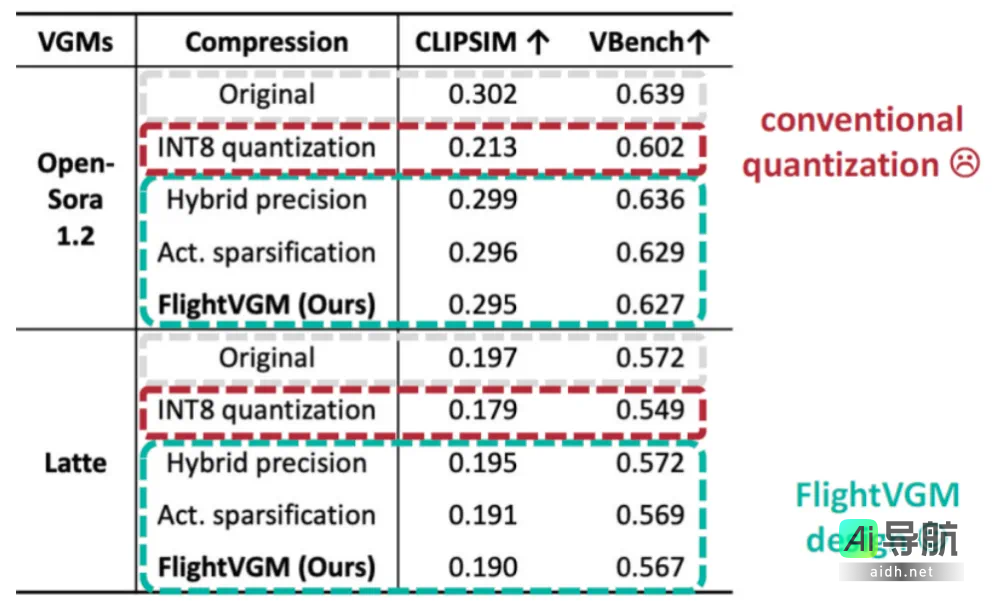
与基准模型对比,FlightVGM 对模型精度的影响几乎可以忽略不计(平均损失仅为 0.008),而全 INT8 量化时的平均损失则为 0.042。同时,在实际的视频生成效果上,FlightVGM 所生成的视频与原始模型保持了较好的相似度。
性能评估
在 NVIDIA 3090 GPU 上,FP16 精度下,AMD V80 FPGA 的峰值算力相较之下差距超过 21 倍。然而,基于 V80 FPGA 实现的 FlightVGM 在性能和能效上却超过了 GPU。这一成就源于 FlightVGM 充分利用了视频生成模型固有的稀疏相似性与混合精度数据分布特性,并通过软硬件协同创新开辟了一条“算法 – 软件 – 硬件”优化的新路径,成功找到了有效的解决方案。相较而言,GPU由于硬件架构的限制,难以提供相同程度的加速效果,且在稀疏化与定制化计算数据流优化支持方面表现不足。

展望和未来工作
随着 VGM 计算需求的日益增长,FlightVGM 展示了如何通过 FPGA 的软硬件协同创新,实现更高能效的文本生成视频大型模型推理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点
没有相关内容!

暂无评论...