

当今信息时代中,自然语言处理(Natural Language Processing,NLP)扮演着关键角色。为有效处理文本数据,开发人员和研究者正在寻找更强大的工具和框架,其中一个备受推崇的是Transformers库。
Transformers库由Hugging Face公司开发,为解决自然语言处理任务(例如文本分类和命名实体识别)提供了现成的预训练模型和快速解决方案。本教程将帮助您掌握Transformers库,并展示如何实现文本分类和命名实体识别任务。
文本分类任务
在实际应用中,常需对文本进行分类,例如新闻分类和情感分析。Transformers库提供了丰富功能和预训练模型支持。以下是实现文本分类的基本步骤:
- 数据准备:准备文本数据集用于训练和测试,进行数据处理和分割。
- 模型选择:选择适用于文本分类的预训练模型,并根据任务需求进行调整。
- 模型训练:使用Transformers库的API加载预训练模型,微调以适配具体文本分类任务。
- 模型评估:使用测试数据集评估模型性能,进行调优。
命名实体识别任务
命名实体识别(Named Entity Recognition,NER)是自然语言处理中重要任务,涉及从文本中识别人名、地名、组织名等实体。Transformers库为命名实体识别提供简单灵活的解决方案。以下是命名实体识别基本步骤:
- 数据准备:收集并标注含命名实体的数据集,进行数据预处理和分割。
- 模型选择:根据任务需求选择适用的预训练模型。
- 模型训练:加载预训练模型,微调以适配特定命名实体识别任务。
- 模型评估:使用测试数据集评估模型性能,进一步优化。
结论
Transformers库是功能强大的NLP工具,有助于处理文本分类和命名实体识别任务。通过本教程,您将快速掌握并利用Transformers库解决实际自然语言处理问题。无论您是初学者还是有经验的开发者,Transformers库都将提高工作效率,带来便利。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点



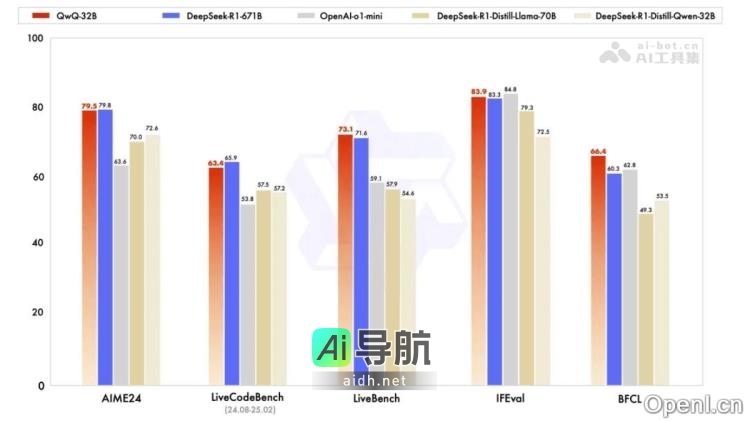



暂无评论...