

Transformer是一种基于注意力机制的模型架构,在自然语言处理领域取得了显著进展。该模型以其卓越性能成为处理各种语言相关任务的首选。本文将探讨Transformer的应用领域、与传统模型的不同之处,以及在语言处理任务中的优势。
一、Transformer的应用领域
Transformer模型广泛应用于机器翻译、文本摘要、情感分析、问答系统等各种语言处理任务中。基于Transformer的预训练模型,如BERT、GPT等,在自然语言处理领域扮演着重要角色。
二、Transformer与传统模型的不同之处
与传统的循环神经网络(RNN)和卷积神经网络(CNN)相比,Transformer采用自注意力机制,更有效地捕捉长距离依赖关系。该机制计算输入序列中不同位置之间的相互依赖,有助于模型更好地理解全局上下文,对语言处理任务尤为重要。
三、Transformer在语言处理任务中的优势
- 模型容量大:Transformer模型拥有庞大的参数空间,能够学习和表征更多语言特征,从而更好地泛化到不同任务上。
- 上下文关注:通过自注意力机制,Transformer能够全面捕捉输入序列中的关系,提供更准确的语义表示,在处理长文本时有更好的效果。
- 预训练与微调:Transformer模型通过大规模预训练学习通用语言表示,再通过微调实现在具体任务上的优化,即使在数据稀缺情况下也可取得出色效果。
Transformer模型的出现极大推动了自然语言处理的发展,在各种语言任务上展现出优势,成为主流语言处理模型。随着对Transformer模型的深入研究,相信它将继续带来更多突破与进展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点



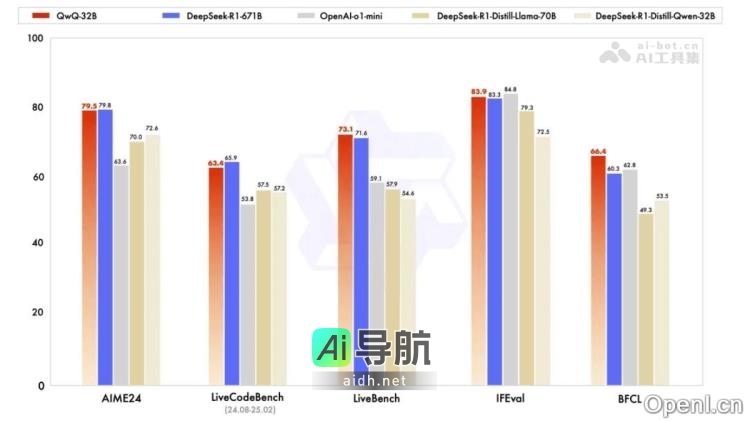



暂无评论...