
科技媒体 Marktechpost 昨日(3 月 1 日)发布博文称,腾讯 AI Lab 联合香港中文大学,创新性地提出了无监督前缀微调 (Unsupervised Prefix Fine-Tuning, UPFT) 方法,旨在显著提高大型语言模型的推理效率。
该方法的核心在于无需处理完整的推理过程,仅需关注模型输出的前 8 至 32 个词元 (tokens),即可有效提升模型的推理能力。UPFT 能够捕捉不同推理路径中共有的关键早期步骤,从而在降低计算开销的同时,实现推理性能的提升。
大型语言模型在语言理解和生成方面表现出色,但提高其推理能力仍然是一项重要挑战。传统的微调方法往往依赖于大量标注数据或复杂的拒绝采样,导致资源消耗巨大。而 UPFT 则另辟蹊径,通过聚焦模型输出的初始 tokens,有效解决了效率问题,并降低了对昂贵监督数据的依赖。
研究发现,针对同一问题,模型生成的各种推理路径的初始步骤往往具有高度的相似性。UPFT 正是基于这种“前缀自洽性”的观察,无需完整的推理轨迹或大量标注数据,仅利用这些初始标记进行训练。
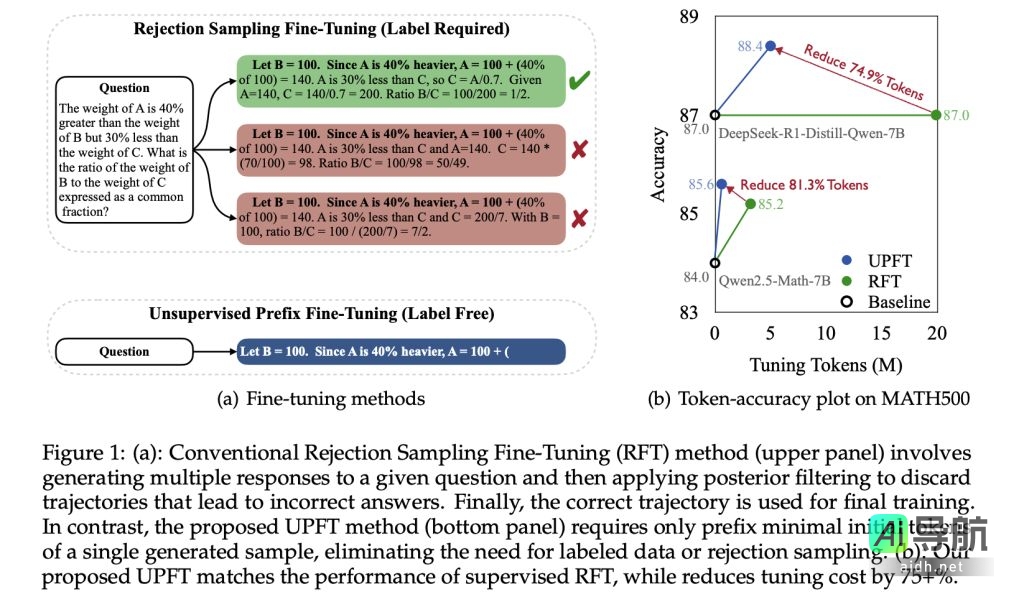
UPFT 采用了贝叶斯推理原理,将正确推理的概率分解为“覆盖率”和“准确性”两部分。通过训练早期 tokens,UPFT 在探索多样化推理路径的同时,确保了结果的可靠性。实验结果表明,UPFT 可将训练中处理的 tokens 数量减少高达 95%,并显著降低时间和内存需求。
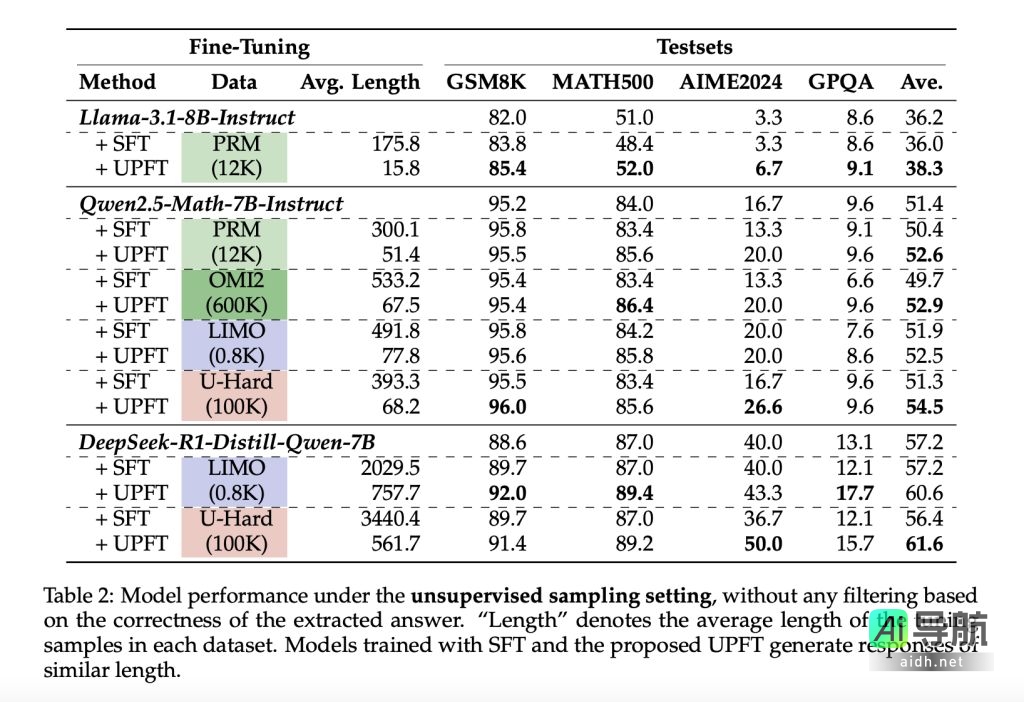
UPFT 在 GSM8K、MATH500、AIME2024 和 GPQA 等推理基准测试中表现出优异的性能。例如,在 Qwen2.5-Math-7B-Instruct 模型上,UPFT 在减少训练和推理 tokens 的同时,提高了平均准确率。在复杂推理任务中,UPFT 的性能提升尤为显著,这表明早期推理步骤蕴含着解决问题的关键信息。
AI工具库附上参考地址:
- The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models
- Tencent AI Lab Introduces Unsupervised Prefix Fine-Tuning (UPFT): An Efficient Method that Trains Models on only the First 8-32 Tokens of Single Self-Generated Solutions
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点








暂无评论...