近年来,随着大语言模型(LLM)的迅猛发展,人工智能正步入多模态整合的新纪元。然而,目前主流的多模态大模型(MLLM)通常依赖复杂的外部视觉模块(例如 CLIP 或扩散模型),这导致系统臃肿、扩展性受限,从而成为跨模态智能演进的主要障碍。
为了应对此问题,华中科技大学、字节跳动与香港大学的联合研究团队提出了一个极简的统一多模态生成框架——Liquid。Liquid 省略了传统的外部视觉模块,采用 VQGAN 作为图像分词器,将图像编码为离散视觉 token,使其与文本 token 共享同一词表空间。这一创新使得 LLM 无需任何结构调整即可“原生”地掌握视觉生成与理解能力,从而彻底消除了对外部视觉组件的依赖。研究团队首次揭示了在统一表征下,LLM 的尺度定律同样适用于多模态能力,并表明视觉生成与理解任务能够相互促进,这一发现为通用多模态智能架构设计提供了新的思路。

- 论文标题:Liquid: Language Models are Scalable and Unified Multi-modal Generators
- 论文链接:https://arxiv.org/abs/2412.04332
- 主页链接:https://foundationvision.github.io/Liquid/
背景与贡献
传统的多模态大模型(MLLM)普遍依赖外部视觉模块(如 CLIP、扩散模型),作为编码器或解码器,并通过特征投影层对齐视觉与文本特征,从而使整体架构变得复杂。近期的研究开始尝试用 VQVAE 替代传统模块,通过将原始像素映射为离散编码,实现图像与文本的统一表征。离散视觉 token 被视为一种新“语言”,扩展至 LLM 的词表中,使得视觉与文本能够以相同的“下一 token 预测”范式进行联合建模,无缝融合多模态信息。尽管早期研究(如 LWM、Chameleon)证实了该范式的潜力,但由于从头训练的方式计算成本高昂,而后续工作引入的扩散模型(如 Transfusion、Show-o)又导致训练目标的割裂,从而制约了模型的效率与灵活性。
本文提出了 Liquid,这一框架能将现有的 LLM 直接扩展成统一的多模态大模型。Liquid 通过 VQVAE 将图像编码为离散视觉 token,使图像与文本共享同一词汇空间,进而实现视觉理解与生成,而无需对 LLM 结构进行修改。研究表明,现有 LLM 凭借其强大的语义理解与生成能力,是多模态扩展的理想起点。相较于从头训练的 Chameleon,Liquid 使训练成本降低了100 倍,同时提升了多模态能力。研究团队还探索了从 0.5B 到 32B 的六种不同规模 LLM 的扩展性能,涵盖多种模型系列,并揭示了三大核心特性:
a. 尺度规律统一性:在视觉生成任务中,验证损失与生成质量遵循与语言任务一致的缩放规律;
b. 规模化解耦效应:多模态训练下受损的语言能力随模型规模扩大而逐渐恢复,表明大模型具备无缝处理多任务的能力;
c. 跨任务互惠性:视觉理解与生成任务通过共享表征空间实现双向促进,验证统一建模的联合优化优势。
极简多模态架构 Liquid
Liquid 采用一致性处理框架,将图像与文本置于同等地位。基于 VQVAE 的图像分词器将输入图像转换为离散编码,并与文本编码共享相同的词汇表和嵌入空间。经过混合的图像 token 和文本 token 被输入 LLM,以“下一 token 预测”的形式进行训练。
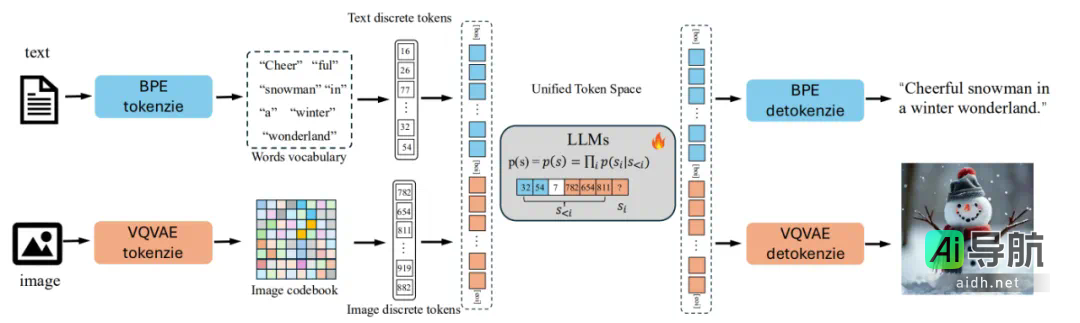
图像分词器:Liquid 采用与 Chameleon 相同的 VQGAN 作为图像分词器,将 512×512 的图像编码为 1024 个离散 token,并嵌入至大小为 8192 的码本。这些离散图像 token 被附加至 BPE 分词器生成的文本码本中,扩展了 LLM 的词表,升级其语言空间,使之包含视觉与语言元素的多模态空间。
架构设计:Liquid 基于现有的 LLM 进行构建,本文以 GEMMA-7B 为基础模型,验证其在多模态理解、图像生成及纯文本任务中的性能。通过对 LLAMA-3、GEMMA-2 和 Qwen2.5 系列模型(规模从 0.5B 到 32B)的扩展实验,全面研究了其多模态扩展行为。Liquid 未对 LLM 结构进行任何修改,只增加了 8192 个可学习的图像 token 嵌入,保留了原有的“下一 token 预测”训练目标及交叉熵损失。
数据准备:为保持现有 LLM 的语言能力,从公开数据集中采样了 30M 文本数据(包括 DCLM、SlimPajama 和 Starcoderdata),总计约 600 亿文本 token。而针对图文对数据,使用 JourneyDB 及内部图文数据,构建了 30M 高质量图像数据,总计 300 亿图像 token。
始和结束标记,[boi]和[eoi]为新增的图像token的起始和结束标记。在规模扩展实验中,对每个模型规模,分别使用30M纯文本数据、30M文本到图像数据及60M的混合数据训练三个独立版本,并评估它们在一系列任务中的性能。
统一多模态模型尺度规律探索
本文探讨了规模从0.5B到32B的六种大型语言模型(LLM)在经过混合模态训练后的视觉生成性能。随着模型规模的增加及训练迭代次数的增长,验证损失呈现出稳定下降的趋势,而token准确率和视觉问答(VQA)分数则持续上升。在相同的训练FLOPs下,较小的模型能够更快地达到较低的验证损失和更高的VQA分数,但较大模型最终能够实现更高的评估指标。这或许是由于较小的模型可以更迅速地完成更多的训练步骤,从而迅速适应视觉信息,但其性能潜上限较低,难以获得高质量的视觉生成结果。
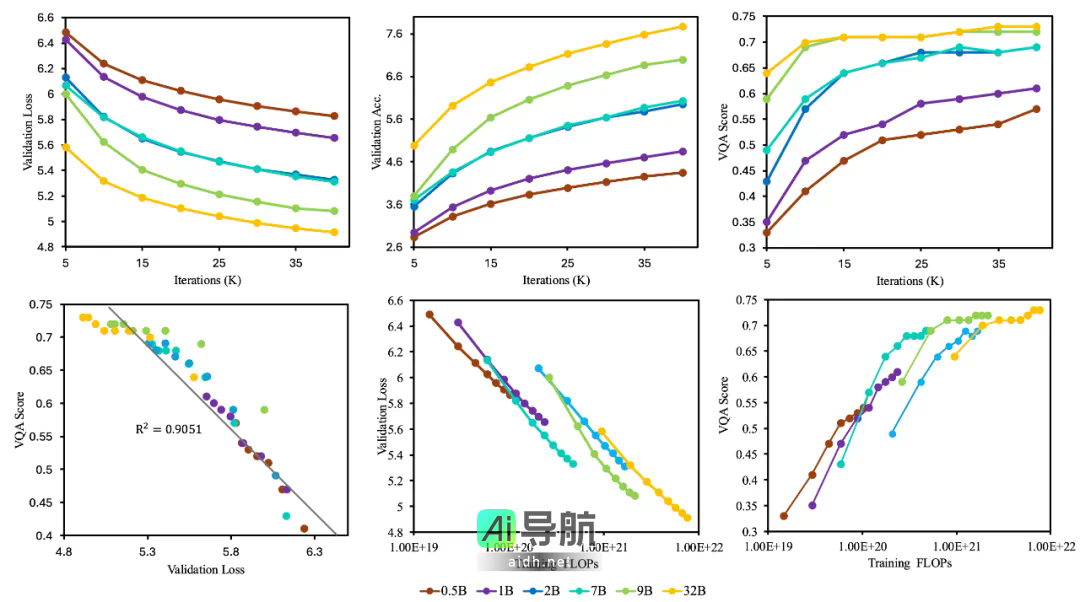
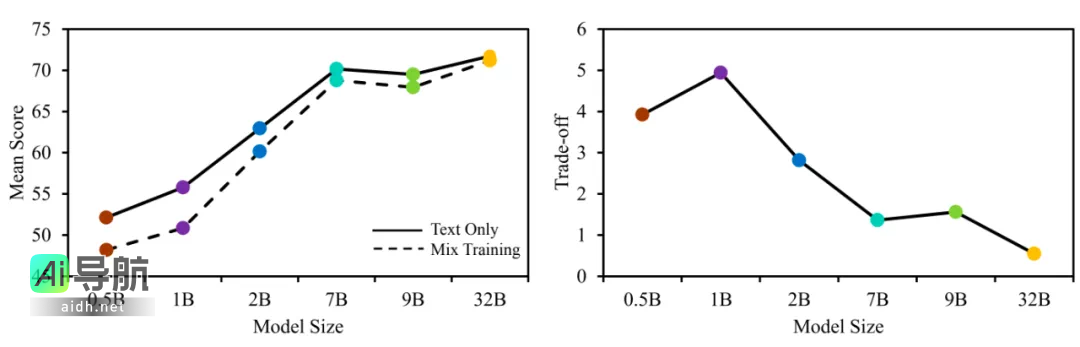
为探究视觉生成能力是否影响语言能力,文章比较了在不同模型规模下,使用30M纯语言数据训练与60M多模态混合数据训练的模型在语言任务上的表现。对于较小模型来说,混合训练时存在一定的权衡现象:1B模型在多模态训练后语言任务的性能下降了8.8%,而7B模型的下降幅度为1.9%。然而,随着模型规模的增加,这种权衡逐渐减弱,32B模型几乎实现了零冲突共生(语言能力保留率为99.2%),这表明较大模型具备充足的能力,能够同时处理视觉与语言空间的生成任务。
理解与生成的相互促进
为探讨Liquid统一范式中理解与生成任务之间的交互关系,研究团队设计了一组消融实验:以10M纯文本、10M视觉生成和10M视觉理解数据(共计30M)作为基线,分别额外增加10M生成数据或理解数据进行对比训练。实验结果表明,增加理解数据能够显著提升生成任务的性能,反之增加生成数据也可增强理解能力。这一突破性发现表明,当视觉理解与生成共享一个统一的模态空间时,两者的优化目标具有同源性——均依赖于语言与视觉信息的深度对齐与交互,从而形成跨任务的协同效应。该发现不仅验证了多模态任务联合优化的可行性,更揭示了LLM作为通用生成器的潜在本质:在单一模态空间下的跨任务互惠可大幅降低训练成本,推动多模态能力的高效进化。

模型性能
视觉生成实验效果
在GenAI-Bench评测中,Liquid在基础与高级文本提示下的整体得分均超越所有自回归模型,其生成的图像与文本在语义一致性方面显著领先。更值得关注的是,Liquid在使用远少于扩散模型(如SD v2.1和SD-XL)的数据量的情况下,实现了与之相当甚至更优的性能,证明了基于LLM的跨模态学习在语义关联捕捉与训练效率上的双重优势。
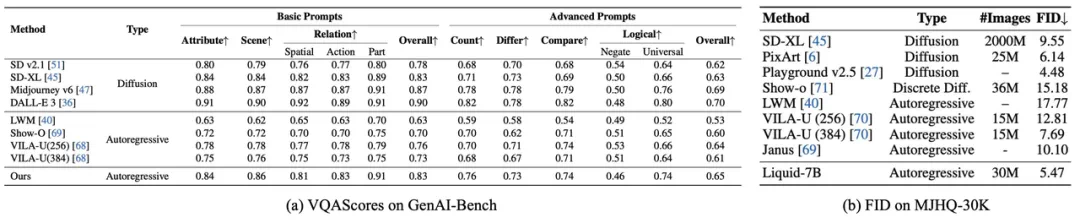
在MJHQ-30K评测中,Liquid以FID=5.47刷新了自回归模型的界限,不仅大幅领先同类方法,还超越了大多数知名扩散模型(仅次于Playground v2.5),证明了LLM在图像美学质量上能够与顶尖生成模型相抗衡。
语言能力保留
在多项经典语言能力评估基准上,Liquid在大部分任务中超越了成熟的LLAMA2和经过大规模混合预训练的多模态语言模型Chameleon,展示了其语言能力未出现衰减。与Chameleon相比,Liquid基于预先具备优秀语言能力的丰富现有LLM进行训练,实现了视觉生成与理解能力的扩展,同时成功保留了语言能力,证明了Liquid能够将视觉生成与理解能力扩展到任意结构和规模的LLM中。
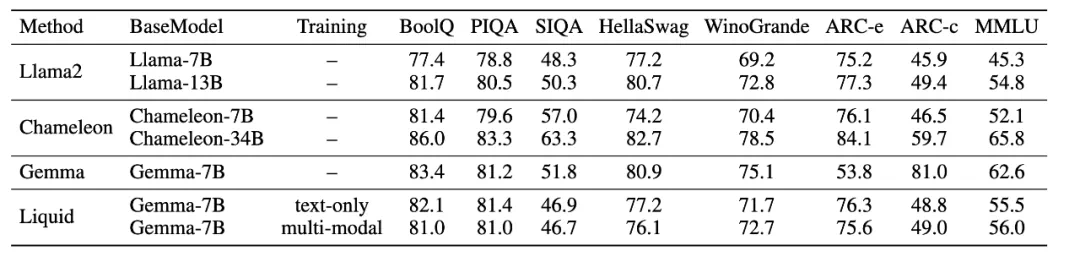
视觉理解能力
在视觉理解任务中,Liquid的性能显著超过了采用标准VQVAE的同类模型(例如LWM、Chameleon、Show-o)。尽管其表现仍略逊于依赖于连续视觉token的主流模型(如LLaVA),但是研究团队通过引入Unitok图像分词器(结合图文特征对齐训练,*标结果),使得模型的理解能力得到了显著提升,接近LLaVA的水平。这验证了基于离散编码的多模态大模型具备突破CLIP编码器限制的潜力。
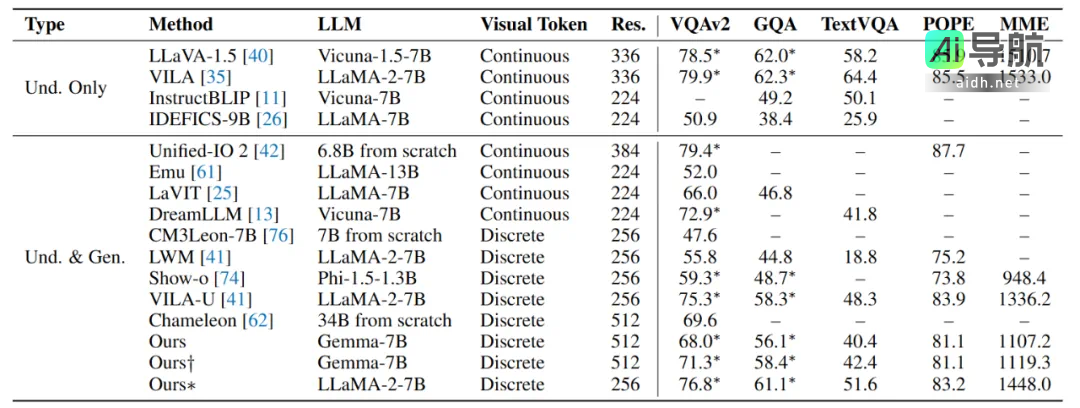
总结
综上所述,本文提出了Liquid,一种极简的统一多模态生成与理解任务框架。与依赖外部视觉模块的传统方法相比,Liquid通过视觉离散编码直接复用现有大型语言模型以处理视觉信息,实现了图像生成与理解的无缝融合。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点
没有相关内容!

暂无评论...