
本文深入探讨了大语言模型在预训练数据选择方面的重要性,并介绍了一种名为 DataMan 的数据管理器。该管理器旨在通过对预训练数据进行质量评分和领域识别,从而优化 LLM 的预训练过程。此项研究由浙江大学和阿里巴巴千问团队合作完成。
在 Scaling Law 的背景下,预训练数据的选择显得愈发重要。然而,现有的方法往往依赖于有限的启发式规则和人为直觉,缺乏全面且明确的指导方针。为此,本研究提出了 DataMan 数据管理器,它能够从 14 个质量评估维度对 15 个常见应用领域的预训练数据进行全面质量评分和领域识别。通过大量的实验,利用 DataMan 筛选出的部分数据进行模型训练,胜率最高可达 78.5%,且性能超越了使用多 50% 数据训练的模型。

- 论文标题:DataMan: Data Manager for Pre-training Large Language Models
- 作者单位:浙江大学 & 阿里巴巴
- 论文链接:https://arxiv.org/abs/2502.19363
一、逆向反思指导质量标准
随着大语言模型(LLM)的快速发展,数据在提升模型性能方面的作用日益受到重视。当前的数据选择方法主要依赖于有限的手工规则和直觉,缺乏全面且明确的指导原则。为解决这一问题,作者提出了“逆向思维”的概念,即通过提示 LLM 自我识别哪些质量标准对其性能有益,从而指导数据选择。
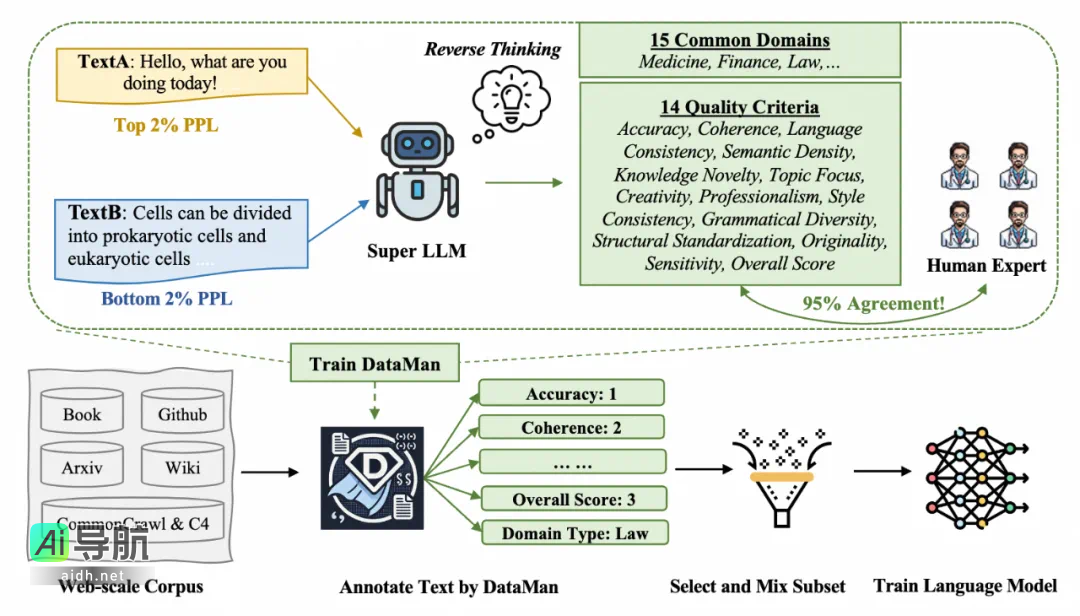
具体而言,该过程包含以下四个步骤:
1)分析文本困惑度的异常: 通过分析预训练所使用的文本数据,特别是困惑度 (PPL) 处于前 2% 和后 2% 的文本,来理解哪些文本特征与困惑度异常相关。此步骤使用一个超级 LLM(Super LLM)来分析这些异常现象背后的原因,并试图找出哪些文本特征对 LLM 的性能具有积极影响。
2)迭代提炼质量标准: 通过上述分析,作者迭代提炼出了 13 个与文本质量相关的标准。这些标准包括准确性、连贯性、语言一致性、语义密度、知识新颖性、主题聚焦、创造性、专业性、语法多样性、结构标准化、风格一致性、原创性和敏感性。
3)构建全面的质量评分体系: 除上述 13 个质量标准外,作者还构建了一个综合性的评分标准,称为“总体评分”(Overall Score)。该评分标准综合考虑了上述 14 个标准,旨在提供一个更全面的文本质量评估。
4)验证质量标准的有效性: 为验证这些质量标准的有效性,超级 LLM 将对这些标准进行评分,并与人工评分进行比较。结果表明,超级 LLM 的评分与人工评分具有超过 95% 的一致性,这证实了这些质量标准的有效性。
二、数据卷王 DataMan
DataMan 是一款综合性的数据管理器,能够对文本进行质量评分和领域识别,旨在促进预训练数据的选择和混合。DataMan 训练和管理数据的过程主要包括以下几个步骤:
1)数据标注: DataMan 模型首先对 SlimPajama 语料库进行标注,标注内容包括 14 个质量评分标准和 15 个常见的应用领域。标注过程通过提示 Super LLM 生成文本的评分,并使用这些评分来创建一个用于模型微调的数据集。
2)模型微调: 使用 Qwen2-1.5B 作为基础模型,通过文本生成损失进行微调。在微调过程中,DataMan 模型学习如何根据给定的文本自动评分和识别领域。
3)数据采样: 基于 DataMan 模型对数据的质量评分和领域识别,可以采用不同的数据采样策略。例如,通过 top-k 采样,根据质量评分和领域分布概率,从源和领域分布中采样数据,以最大化样本的代表性,同时确保数据源和领域的多样性。
三、实验设置
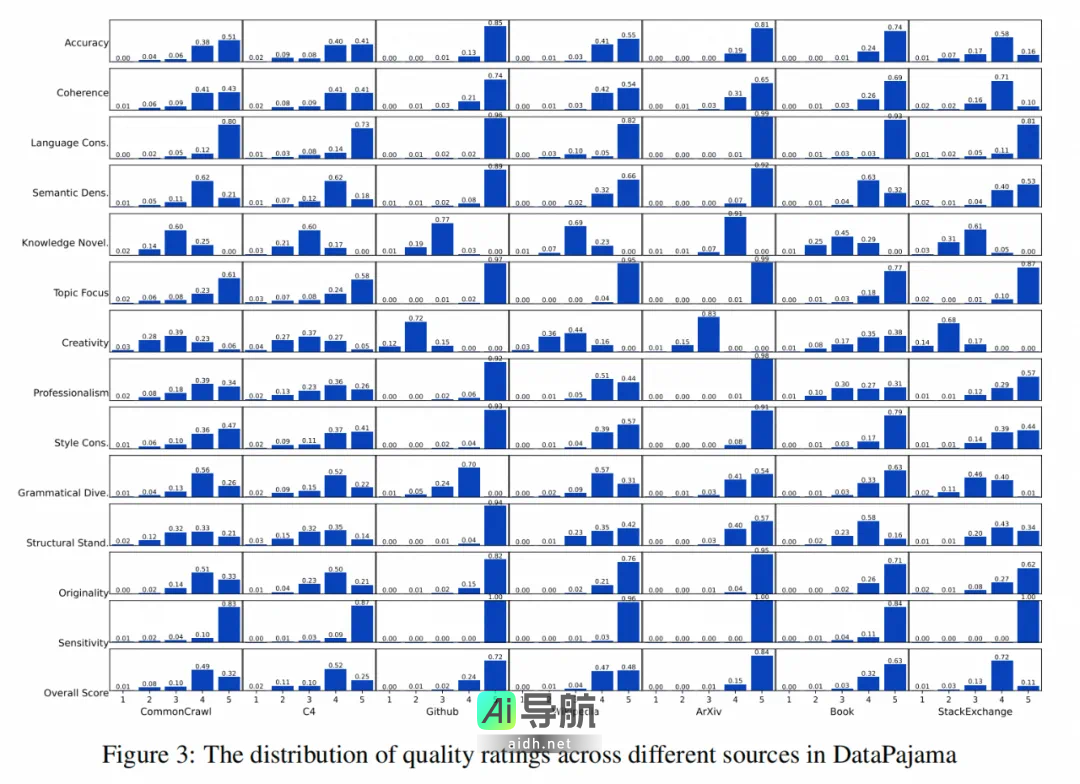
DataPajama 是一个经过清洗和去重的 447B token 预训练语料库,DataMan 模型已为其中的每个文档打上 14 个质量评分和 15 个领域类型标签。
*DSIR**:采用重要性重采样(DSIR)方法选取与英语维基百科或书籍领域相似的文档。
- Perplexity Filtering:根据困惑度进行数据过滤。
- Sample with Qurating:依据Qurating提出的四项质量标准(写作风格、事实准确性、教育价值和所需专业知识)进行样本采样。
- Sample with DataMan:基于DataMan提供的13个质量标准进行样本选取。
模型训练: 使用Sheared-Llama-1.3B模型架构,对从DataPajama中筛选出的30B token子集进行训练。训练的设置包括采用RoPE嵌入、SwiGLU激活函数以及Adam优化器等。
四、实验发现
通过大量实验,本研究验证了DataMan方法的有效性,且通过DataMan选择的数据进行训练的模型在多个下游任务中展现了卓越的性能表现。
DataMan性能如何?
如表所示,使用DataMan数据进行训练的模型在语言建模、任务泛化能力以及指令遵循能力方面均显著优于使用均匀采样的基线模型。此外,基于DataMan的13个质量标准进行采样,相较于均匀采样在模型性能上有显著提升,特别是在上下文学习(ICL)任务中。
在指令遵循能力方面,作者的模型持续超越当前的技术最优(SOTA)基线,整体得分达到了令人印象深刻的78.5%。
在垂直领域内的持续预训练?
作者们利用DataMan的领域识别功能,过滤掉医学、法律和金融领域的数据,进而进行持续预训练,以构建领域特定的模型。如图展示,模型性能获得了进一步提升,从而验证了DataMan在领域混合方面的能力。
数据量与模型性能之间的关系?
本研究还对一个更大规模的60B子集进行了相同的方法抽样,从而探讨数据量对模型性能的影响。如表所示,模型在ICL等下游任务中都有显著提升。
PPL与ICL的失调?
下图展示了10个下游任务中所有模型的困惑度(PPL)与上下文学习(ICL)性能之间的关系,并计算了Pearson和Spearman相关系数。结果显示,在LogiQA和MMLU任务中这种失调尤为显著。进一步分析指出两大主要原因:一是领域不匹配:预训练通常使用广泛的通用语料库,导致模型在公共文本上表现出较低的困惑度。尤其是像MMLU这样的任务,涉及57个不同的专业领域(如抽象代数和解剖学),可能由于领域不匹配而在ICL表现受损。二是ICL任务的复杂性:许多ICL任务涉及复杂的推理过程,而不仅仅是简单的文本生成。因此,困惑度的评估往往难以准确反映模型性能,这在LogiQA中尤为明显,该任务通过来自公务员考试的专家撰写的问题来评估人类的逻辑推理能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点


暂无评论...