 在 GSM8K 数据集上进行训练的结果表明,Qwen2.5-7B 的准确率及格式遵循能力均在30步以内迅速收敛,准确率(左图)始终维持在90%以上,而格式遵循能力(右图)更是达到了100%.
在 GSM8K 数据集上进行训练的结果表明,Qwen2.5-7B 的准确率及格式遵循能力均在30步以内迅速收敛,准确率(左图)始终维持在90%以上,而格式遵循能力(右图)更是达到了100%.
本文介绍复旦大学知识工场实验室肖仰华教授、梁家卿青年副研究员团队的最新研究成果:一个简洁高效的R1-zero自发反思能力复现项目。
DeepSeek研究中反复提及的“Aha Moment”(顿悟时刻),指的是模型训练过程中突然展现出类似人类自我反思和策略调整能力的现象。 DeepSeek 论文中提到的 Aha Moment。
DeepSeek 论文中提到的 Aha Moment。
DeepSeek-R1-zero 通过强化学习实现了大模型顿悟时刻的自发涌现,引发了广泛的解读和复现尝试。其中,基于GRPO(Group Relative Policy Optimization)强化学习方案的复现项目备受关注,但现有项目普遍存在代码复杂度高、对部署环境依赖性强、资源利用率低、可读性和可维护性差等问题。
为此,复旦大学知识工场实验室肖仰华教授、梁家卿青年副研究员团队基于GRPO算法,高效复现了R1-zero的自发反思能力。该项目(Simple-GRPO)第一版代码现已开源并发布至Github。 代码地址:https://github.com/lsdefine/simple_GRPO。
代码地址:https://github.com/lsdefine/simple_GRPO。
与现有开源R1-zero复现项目相比,本项目具有以下优势:
代码简洁,依赖库少:代码量仅200余行,仅依赖deepspeed和torch等基础深度学习库。
资源消耗低:通过模型解耦与分离降低算力需求,可在单张A800 (80G)和单张3090 (24G)显卡上完成7B模型的训练。根据AutoDL平台计费标准,A800 (80G) 5.98元/小时,3090 (24G) 1.32元/小时。项目作者实测,模型在一小时内即可出现“顿悟时刻”,单次实验成本极低。
项目概述
本项目代码简洁,GRPO算法实现仅需200余行代码,且仅依赖deepspeed和torch等基础深度学习库,无需ray等复杂框架。具体实现细节如下:
① 参考模型分离:
参考模型被解耦,可在不同GPU上运行(甚至可在3090显卡上运行)。此举避免了在同一GPU上运行参考模型和训练模型,防止torch多进程机制创建多个副本造成显存浪费,从而支持在A800 (80G)上训练7B模型。
② 核心损失计算:
损失计算公式基于Hugging Face的trl库实现。
③ 训练环境与过程
项目使用一张A800 (80G)显卡进行Zero-Stage 2优化,另一张A800 (80G)显卡用于参考模型推理,参考模型分离提高了GRPO训练效率。
在上述训练环境下,Qwen2.5-3B训练60步耗时12分34秒,Qwen2.5-7B训练60步耗时16分40秒。在训练前30步内,Qwen2.5-7B和Qwen2.5-3B均出现了“顿悟时刻”现象。示例如下:
- Qwen2.5-3B(第20步)

 中文翻译如下:
中文翻译如下:
「 … 要计算Camden画的鸡蛋比Arnold多多少,我们从Camden画的鸡蛋数量中减去Arnold画的鸡蛋数量。因此,21-28 = -7。然而,这个结果在题设背景下无意义,因为Camden画的鸡蛋不可能比Arnold少。让我们重新审视初始解题步骤:我们需要验证关于Camden和Sarah的鸡蛋数量关系的初始假设是否正确。… -7」
- Qwen2.5-7B(第20步)

 中文翻译如下:
中文翻译如下:
「 … 因此,Joanne从普通苹果树上摘了350个苹果。但是,这似乎不正确,因为总数应该是500个,我们已经计算了150个,只剩下350个普通苹果树上的苹果,这与总数矛盾。让我们重新评估一下 。
Qwen2.5-3B:
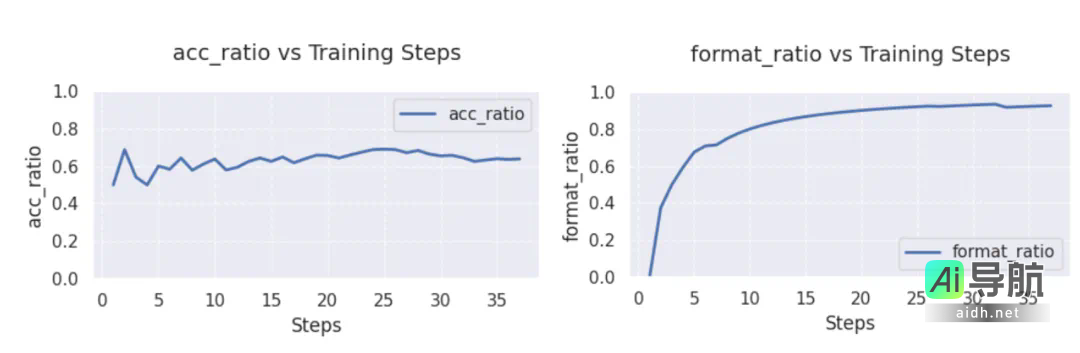
在 GSM8K 与 Math 混合数据集上进行训练。从图中可以观察到,Qwen2.5-3B 的准确率在经过五轮优化后,稳定维持在60%以上,最高可达70%;而它的格式遵循能力在经历30轮后接近100%.
- Qwen2.5-7B:
在 GSM8K 数据集上进行训练的结果表明,Qwen2.5-7B 的准确率及格式遵循能力均在30步以内迅速收敛,准确率(左图)始终维持在90%以上,而格式遵循能力(右图)更是达到了100%.
改进方向
近期,本项目将继续推出以下优化版本,敬请期待。
组内答案同质性问题
依据 GRPO 算法中的分组策略,若组内所有答案均正确或全部错误,则针对奖励函数的有效分配将受限,进而导致强化学习缺乏具有对比性的训练信号,模型难以实现收敛。后续将通过实时监控训练过程中答案的分布情况,对同质化的答案实施重新采样与分组,以提供有效的对比信号。
长思维链 (CoT) 显存占用问题
当模型生成较长的思维链 (CoT) 时,文本序列的长度将显著增加,从而导致显存占用的显著上升。针对这一问题,未来将考虑分拆组别、减小批次大小,或采用分阶段处理长序列的方法,以降低训练过程中的 GPU 内存占用,从而提升训练效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点

暂无评论...