DeepSeek于今日正式启动了为期五天的开源成果发布计划,首个亮相的项目为FlashMLA。该开源项目结合了先进的MLA算法和GPU优化技术,旨在为大规模模型推理提供一套高性能、低延迟的解码方案。
FlashMLA是一款特别为Hopper GPU(如H800 SXM5)优化的高效MLA解码内核,旨在加速大模型的计算任务,尤其是在NVIDIA的高端显卡上显著提升其性能。
借助FlashMLA,开发者在处理大规模语言模型时,能显著提高处理效率并降低延迟。与传统解码器相比,FlashMLA在处理可变长度序列时表现出更高的计算效率。

PPIO派欧云对FlashMLA在主流Hopper GPU(包括H20、H100、H200、H800)上的性能进行了评测。在深入分析评测结果之前,首先了解一些相关背景知识。
科普时间:何为Hopper GPU、解码内核和MLA?
•Hopper GPU:由NVIDIA推出的下一代高性能GPU架构,专为人工智能和高性能计算(HPC)设计。该架构采用先进的制程技术和创新设计理念,在处理复杂计算任务时表现出卓越的性能和能效。主流的Hopper GPU包括H20、H100、H200和H800。
•解码内核:专门加速解码任务的硬件或软件模块。在人工智能推理过程中,解码内核能够显著提升模型推理的速度与效率,尤其是在处理序列数据时。
•MLA:多头潜在注意力(Multi-head Latent Attention)的简称,MLA对KV缓存的需求自量化较轻,这使得其在处理长序列时更具扩展性,同时性能优于传统的多头注意力机制(Multi-Head Attention, MHA)。
FlashMLA性能实测
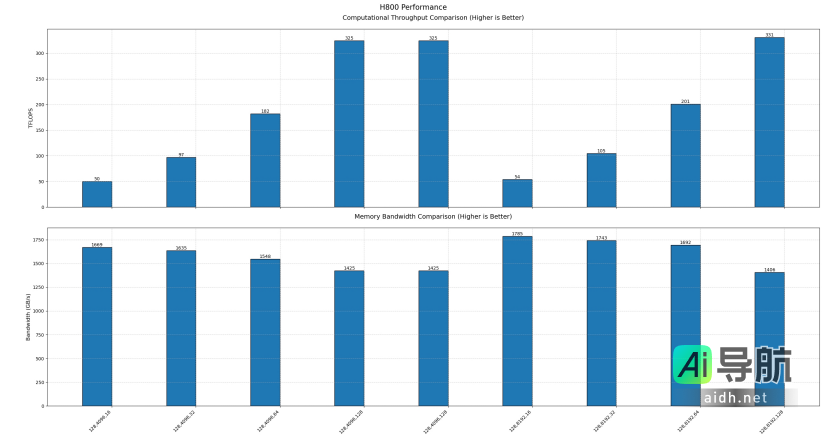
DeepSeek官方宣称,FlashMLA在H800 SXM5 GPU上可实现高达3000 GB/s的内存速度上限及580 TFLOPS的计算性能上限。PPIO派欧云对FlashMLA 在不同参数配置下的性能进行了全面评测。为了直观展示结果,横坐标依次表示测试的参数配置,具体包括:
•批次大小(Batch Size)
•序列长度(Sequence Length)
•注意力头的数量(Number of Attention Heads)
评测结果如下:
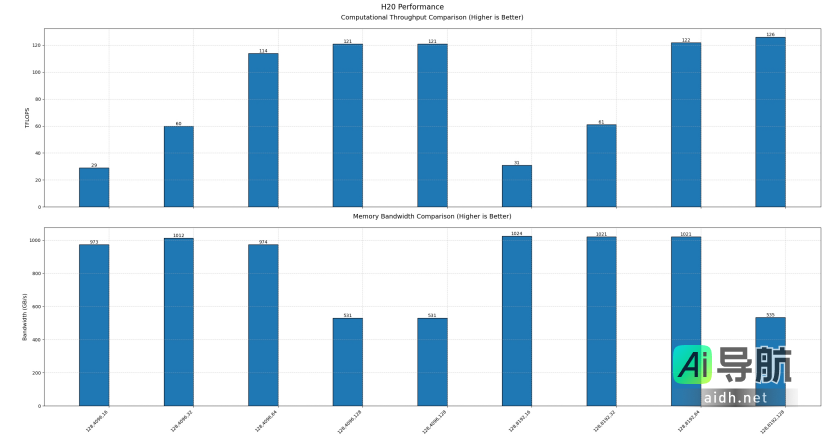
•H20 GPU:内存速度上限为1024 GB/s,计算性能上限为126 TFLOPS。
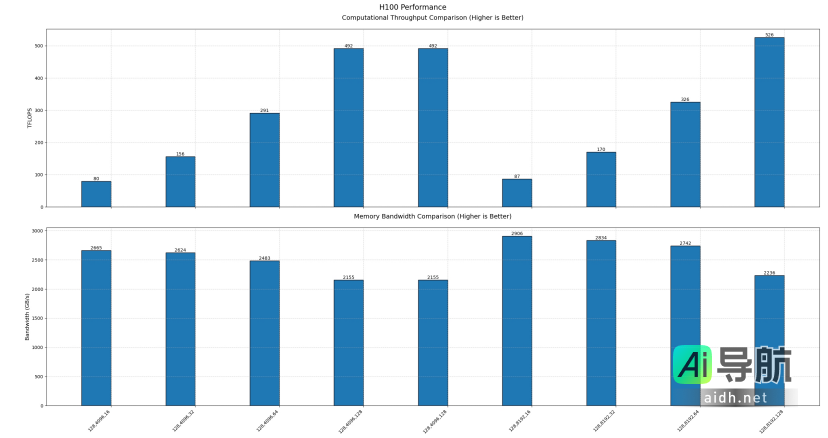
•H100 GPU:内存速度上限为2906 GB/s,计算性能上限为526 TFLOPS。
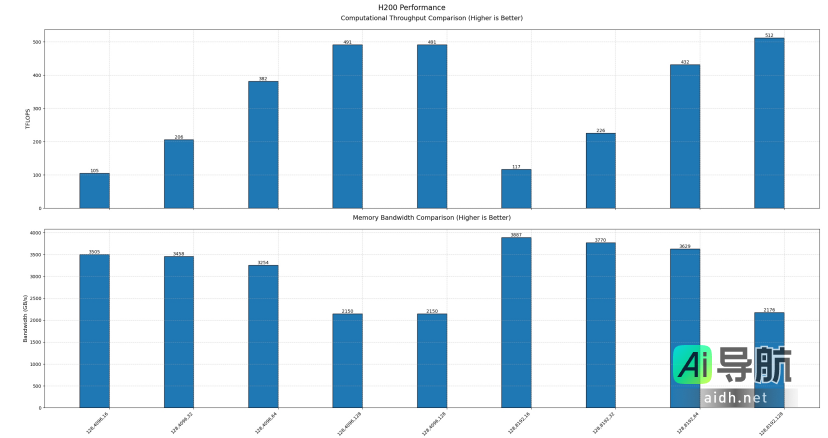
•H200 GPU:内存速度上限为3887 GB/s,计算性能上限为512 TFLOPS。
•H800 GPU:内存速度上限为1785 GB/s,计算性能上限为331 TFLOPS。
以上测试结果基于官方的测试脚本进行。由于官方对于最佳参数配置尚未披露,数据可能未能达到理论极限。
FlashMLA对主流推理框架的影响
FlashMLA的发布不仅引起了开发者的关注,同时也引发了主流推理框架的重视。两大热门框架vLLM和SGLang对FlashMLA做出了积极回应。
vLLM团队预计将很快实现与FlashMLA的集成。技术上,FlashMLA基于PagedAttention的实现,与vLLM的技术栈高度兼容,集成后有望进一步提升vLLM的推理性能。
SGLang则持续使用已经合并的FlashInferMLA。根据他们的评测,FlashInferMLA的性能与FlashMLA基本持平。