随着2025年新年的到来,DeepSeek R1 与 V3 重磅发布,其卓越的语言建模与推理能力迅速引发全球 AI 社区的广泛关注。在这一热潮中,隐藏在超大规模模型背后的一个重要技术问题逐渐浮现:如何使千亿参数的超大规模 AI 模型真正实现商业级的推理速度?这一问题的答案,蕴藏于推理引擎 SGLang 的代码仓库中。该项目由 LMSYS Org 主导,受到了 xAI、NVIDIA 和 AMD 等科技巨头的青睐,正通过多项关键技术突破重新定义 LLM 推理的效率极限。

自 DeepSeek 模型发布之日起便实现了最佳适配,并持续在 SOTA(State Of The Art)性能榜首保持领先,SGLang 的发展轨迹揭示了一个开源项目生存的核心法则:依托工程创新,克服开发者在性能优化方面的最大挑战。
SGLang 通过诸如多头潜在注意力优化(Multi-head Latent Attention Optimization)、数据并行路由(Data Parallelism Router)、鹰眼投机解码(Eagle Speculative Decoding)等前沿技术方案,长期维持着开源模型顶尖的推理速度和吞吐量。
然而,SGLang 的发展并未止步于此。当 Agent 团队的工程师将其应用于智能体的部署时,当开发者将其优化策略融入 NVIDIA Triton 内核时,当全世界的研究者高强度地使用 DeepSeek 本地部署时,该项目的真实价值便显现出来:它不仅是长期卓越的推理引擎,更是开源社区集体智慧的结晶。本文将从核心技术突破、系统级优化以及开发者生态等多个维度,详细解读 SGLang 独特的演进历程。
一、DeepSeek 模型的持续优化及架构适配工程实践
图源: DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
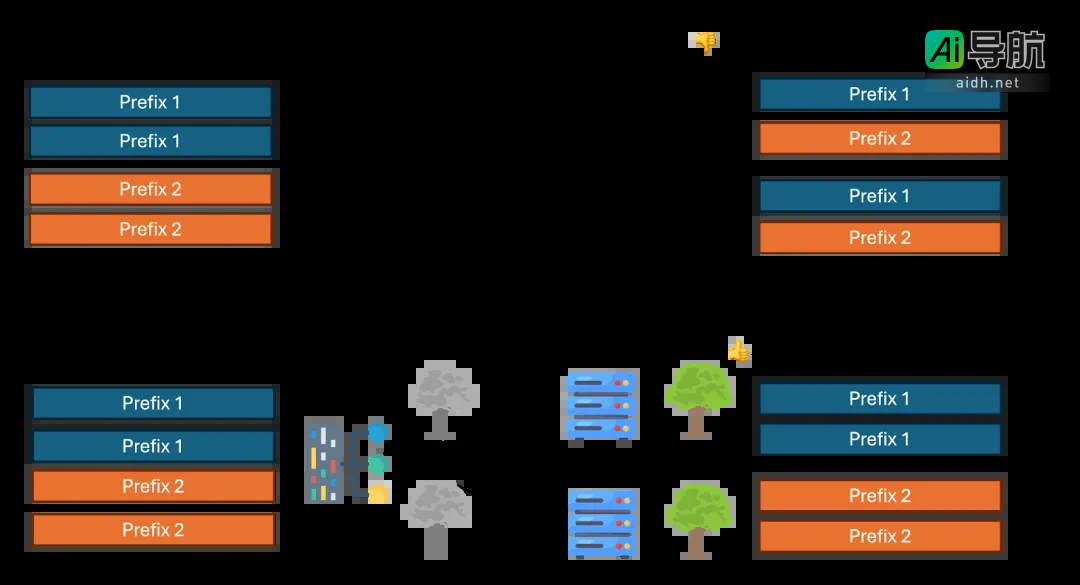
自 DeepSeek V2 发布以来,SGLang 团队对 DeepSeek 系列模型的多头潜在注意力(MLA)架构进行了深入优化。这些技术覆盖了数据并行注意力(Data Parallelism Attention)、多节点张量并行(Multi Node Tensor Parallelism)及块级 FP8 量化(Block-wise FP8),在解码计算、显存管理与多节点协同等多个环节实现了显著提升。
在对多头潜在注意力(MLA)进行优化时,团队通过权重吸收的方法重新排列计算步骤,确保模型表征能力的同时,合理平衡了计算与内存访问负载,显著减少了解码过程中的冗余计算。在此基础上,针对 MLA 解码核仅保留一个 KV 头的设计,SGLang 团队开发了 Triton 解码核优化方案,该方案允许在同一计算单元内同时处理多个查询头,显著降低了对 KV 缓存的内存访问需求,从而加速了解码流程。此外,团队结合 W8A8 FP8 和 KV 缓存的 FP8 量化技术,开发了 FP8 批量矩阵乘法(BMM)算子,实现了 MLA 高效的 FP8 推理。值得一提的是,MLA 与混合专家(MoE)模块均兼容 CUDA Graph 和 Torch.compile,从而进一步降低小批量推理过程中的延迟。经过这些优化,DeepSeek 系列模型的输出吞吐率较前一版本实现了最高达7倍的加速效果。
针对高并发与大批量数据的实际应用需求,团队在 MLA 注意力机制中引入了数据并行注意力技术。该方案通过将不同类型的批处理(包括 prefill、decode、extend 及 idle 状态)分别分配给各个数据并行工作单元,使每个单元能够独立处理各自的任务。在任务完成后,再在混合专家(MoE)层进行必要的同步操作,从而显著降低了 KV 缓存的重复存储负担,优化了内存使用并支持大批量请求的高效处理。该优化方案专为高 QPS(每秒查询数)场景而设计,用户在使用 DeepSeek 系列模型时可通过命令参数 –enable-dp-attention 一键启用此功能。
在单节点内存受限的情况下,SGLang 团队还推出了多节点张量并行技术,使得超大规模模型(如 DeepSeek V3)能够跨多个 GPU 或节点进行参数分区部署,从而有效突破单节点内存瓶颈。用户可根据实际资源情况,在集群环境中灵活配置多节点张量并行,确保模型在高负载场景下依然保持高效推理和资源利用率。
为了在推理过程中进一步平衡数值精度与计算效率,团队还开发了块级 FP8 量化方案。在激活值量化时,采用 E4M3 格式并通过每个 token 的 128 通道子向量在线 casting 实现动态缩放,从而确保量化后激活值的数值稳定性;权重量化则以 128×128 块为处理单元,使量化过程更加精细,有效捕捉权重分布特性。这一方案已在 DeepSeek V3 模型中默认启用,为模型的高效推理提供了较高的精度保障。
在如此极致的优化下,SGLang 团队实现了从解码计算到内存管理,从单节点优化到跨节点协同的全方位提升。效能革命
在传统推理引擎中,尽管大型模型的推理主要依赖于 GPU 运算,CPU 仍需承担诸如批调度、内存分配及前缀匹配等大量任务。未经过充分优化的推理系统通常会将多达一半的时间耗费在这些 CPU 开销上,从而严重抑制了整体性能。SGLang以其高效的批调度器而闻名,而在 0.4 版本中,团队再度突破,实现了几乎零开销的批调度器。
这一技术的关键在于将 CPU 调度与 GPU 计算进行重叠执行。具体而言,调度器提前运行一批任务,在 GPU 执行当前请求时,同步准备好下一批所需的元数据。这样,GPU 能够始终处于繁忙状态,无需等待 CPU 的调度结果,有效隐藏了如匹配 radix cache 等高开销操作带来的延迟。根据 Nsight profiling 工具的测试结果,在连续进行的五个解码批次中,GPU 保持了高负载状态,未曾出现任何空闲时段(注:该测试以 Triton attention 后端为基础,FlashInfer 后端将在后续版本中进一步优化)。
凭借这一优化,SGLang v0.4 能够充分挖掘 GPU 的计算潜力,在显著提升 batch size 的情况下,较上一版本有了明显的性能提升。特别是在小模型与大规模张量并行场景下,此优化的效果尤为显著。该近零开销的批调度技术已默认启用,用户不需要额外配置,即可享受显著的性能提升。
三、多模态支持:视觉与语言的协同加速
在多模态应用场景中,SGLang 始终与国内外顶尖的多模态技术团队开展深入合作,将先进的视觉与语言处理能力无缝集成至 SGLang 中。目前的解决方案使得系统能够同时处理单图像、多图像以及视频任务,在计算机视觉的三大场景中实现了卓越的性能,为后续多模态应用奠定了坚实基础。
在实现层面,SGLang 通过兼容 OpenAI 的视觉 API 提供服务。该接口不仅能够处理纯文本输入,还能接受交错文本、图像和视频的混合输入,以满足复杂应用场景下多模态数据的协同处理需求。用户无需进行额外开发,即可通过统一的 API 享受便捷而高效的多模态推理体验。
官方提供的基准测试结果显示,在 VideoDetailDescriptions 和 LLaVA-in-the-wild 数据集上,集成后的多模态模型在确保推理准确性的同时,相较于 HuggingFace/transformers 的原始实现,性能最高可提升 4.5 倍。这一加速效果归功于 SGLang Runtime 的高效调度与轻量化设计,使得系统在处理多类型数据时始终保持较高的吞吐率。
截至目前,SGLang 已在多模态支持方面展示出卓越的兼容性与扩展能力,后续还将邀请更多开发者重构相关代码,支持更多模型及最新的 cosmos 世界模型和 -o 流式模型。通过交互式的文本、图像与视频输入,SGLang 不仅极大提升了多模态任务的处理效率,也为实际应用场景中的复杂数据协同计算提供了有力的技术保障。更多详细的使用方法和性能数据,请参考官方技术文档及基准测试报告。
四、X-Grammar:结构化生成的范式重构
在约束解码领域,SGLang 利用 XGrammar 系统在结构化生成方面实现了全新的范式重构,显著突破了传统约束解码的性能瓶颈。
在上下文扩展方面,XGrammar 针对每条语法规则增加了额外的上下文信息检测,从而有效减少与上下文依赖相关的 token 数量。此改进使系统在处理复杂语法时能够更早识别并利用规则隐含的语义信息,进而降低了解码过程中不必要的状态切换开销。
为高效管理多条扩展路径产生的执行状态,XGrammar 采用基于树结构的数据组织方式,构建持久化执行栈。这一设计不仅高效管理多个执行栈,还能在面对拆分与合并操作时保持数据结构的稳定性与高效性,确保整个解码流程始终流畅运行。
在下推自动机结构优化方面,XGrammar 借鉴编译器设计中的内联优化与等价状态合并技术,对自动机中的节点进行了精简。现了高达 10 倍的加速效果。在处理复杂结构化数据和工具调用场景时,XGrammar 不仅显著降低了解码延迟,更为大规模在线服务提供了可靠的性能保障。关于 XGrammar 的更深入介绍,SGLang 团队已在其官方博客中进行了详细阐述,并提供了相关技术文档以供参考。
五、Cache-Aware Load Balancer:智能路由的架构突破
SGLang v0.4 版本引入了创新的 Cache-Aware Load Balancer,为大模型推理系统提供了智能路由的架构突破。该负载均衡器完全采用 Rust 编写,相较于 Python 显著降低了 Service Overhead。其路由算法基于字符级前缀匹配,通过合并后的 Radix Tree 实现无需 Tokenization 的匹配。系统能够根据各工作节点的前缀 KV 缓存命中率进行动态评估,并自动选择缓存命中率较高的节点来处理请求。与传统的轮询调度方式相比,此方案在实际测试中展示了最高可达近两倍的吞吐量提升,以及近四倍的缓存命中率改进。随着工作节点数量的增加,这种优势更为明显,充分体现了负载均衡策略在多节点分布式部署中的卓越扩展性。
为了有效管理缓存资源,SGLang 的负载均衡器内部采用了懒更新的 LRU 淘汰策略,对近似 Radix Tree 中访问频率较低的叶子节点进行定期清理,从而防止内存过度膨胀并保持树结构的高效性。此举不仅优化了内存使用,还为整个推理系统带来了更稳定的缓存性能。在分布式部署场景下,系统通过 HTTP 接口实现了秒级动态扩缩容,允许在集群中快速增减工作节点。得益于这一智能路由设计,SGLang 在多节点集群中的吞吐性能呈现出近乎线性的扩展趋势,为大规模在线服务提供了坚实的性能和可靠性保障。
六、开发者工具链
在可用性和易用性方面,SGLang 提供了与 OpenAI API 兼容的接口层,支持 Chat、Completions、Embeddings 等常见功能,开发者仅需替换端点即可快速无缝迁移。对于更灵活的部署方式,离线引擎模式(Offline Engine)允许单脚本同时驱动多节点推理,无需独立服务化,从而大幅简化了运维成本。
为了使开发者能够深入了解模型状态并进行精细调优,SGLang 内置了 Prometheus 监控集成,可实时追踪吞吐量(Throughput)、延迟(Latency)和显存使用(GPU Memory Pressure)等核心指标。多 LoRA 动态加载(Dynamic LoRA Switching)则允许同一服务在显存复用率高达 90% 的情况下,热切换多个不同的 LoRA 适配器(Low-Rank Adaptation)。约束解码(Constrained Decoding)提供了 JSON、GBNF 等格式的强制校验能力,将生成错误率降至极低水平,满足生产场景对输出格式一致性的严格要求。
七、社区与未来规划
目前,SGLang 在全球范围内已汇聚了 30 余位核心贡献者。在接下来的 2025 H1 阶段中,团队将致力于完善实战场景下的 PD 分离、Speculative Decoding 的长文本优化、推动多级缓存(GPU/CPU/Disk)策略落地,并持续强化并行策略以适配千亿级 MoE 模型。除了推理效果的优化,SGLang 团队还将致力于推理引擎的广泛应用,继续支持 RAG、multi-Agent、Reasoning、RLHF 等领域的 AI 落地。最后,SGLang 也将在算子覆盖率与性能上持续优化,支持更多更广泛的硬件,力争为开源社区提供更加先进的一站式大模型推理方案。
八、新的一年,与社区共赴星辰大海
开源一周年,SGLang 的成长轨迹印证了一个技术真理:顶尖的工程实践,永远诞生于开发者社区的协作共振。从首个支持 Prefix Cache 的推理框架,到斩获 11K Star、月均 10 万下载量的开源明星;从 xAI、NVIDIA、AMD 等巨头的深度集成,到为 DeepSeek 模型提供的最佳开源推理引擎——SGLang 的每一次技术突破,都源于社区开发者的真实需求与共创智慧。
验等。其背后是三十多位核心贡献者与数百位开发者的通力合作。正如 LMSYS Org 组织所倡导的核心理念,技术生态的繁荣绝非个体的奋斗能够成就。当我们见证 SGLang 在 DeepSeek-R1 上实现了显著的吞吐量,并在 128k 长文本场景中达到了超低延迟时,这不仅代表了框架的成功,更是开源社区“百花齐放”的生动写照——从 LinkedIn 的分布式部署实践,到 NVIDIA 的 Triton 内核优化,再到普通开发者提交的数百个性能调优的 Pull Request,每一位参与者都在为大模型的实际应用贡献力量,齐心协力实现这一共同的目标。
如同“百花齐放,春满园”的诗句所言,SGLang 的开源故事正是一个属于开发者的黄金时代的生动体现:在这里,工程师的每一行代码都有可能对数百万用户的体验产生深远影响,研究者的每一个创意都有机会推动技术的边界。SGLang 团队诚挚邀约每一位对该项目感兴趣的朋友加入社区,参与 Slack 和 GitHub 上的技术讨论,并在全球的 Meetup 中分享真实的实践经验——因为下一个可能改变行业的优化方案,或许就源于您一次简单的 git commit。
- GitHub 仓库: https://github.com/sgl-project/sglang
- Slack 社区:slack.sglang.ai
- DeepSeek 优化指南: https://docs.sglang.ai/references/deepseek.html
立即体验最新版本的 SGLang,将大模型推理提升到新的高度!