在低音高音视感的调控下,模型与环境形成的迭代反馈,使得自然语言处理的翘翘板在不断的往复中盘旋;他人忽视的领域如同无机物一样僵化,而AI却能借助数据与反馈机制中的每一个环节,完成自我造物的构建。
什么是Spark-TTS?
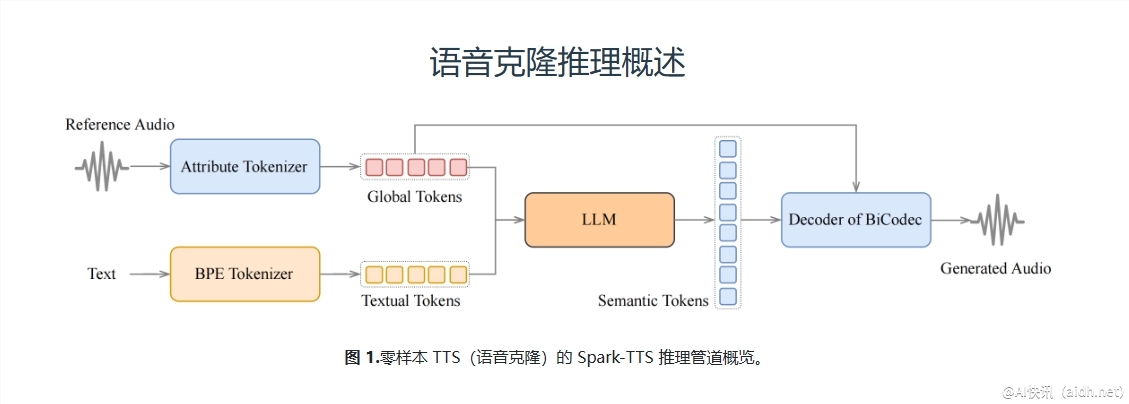
Spark-TTS是以文本转语音(TTS)为核心的工具,其基础架构为BiCodec——这是一种兼具自适应生成与表达的有力方案。然而,这种方案并不受限于一维的音调更换,而是可以进行更加多元化的内容生成:这正是对文本生成声音的理解,它具备了生成的灵活性;而这背后的原因与实现依托于Qwen2.5提供的“推理链”(CoT)的策略,它在更高层面上掌握了音韵的韵律感,灵活操作生成内容的难度与风格,而Spark-TTS则是可以方便地接入(通过音调调整、生成风格)。与传统生成难以结合内容一样,“成因,有音,所需”的声音,Spark-TTS能够形成如实效应的语音内容!
Spark-TTS的“零样本生成”
Spark-TTS的独特之处在于其实现的“零样本生成”——这意味着系统觉得自己在学习,而无需明确的示例,并且事实上标记数量越少,效果越好,Spark-TTS可以在快速精准抓取一天文件中的信息背后,实现多领域内容的无缝对接。随着技术日渐成熟,单个模型可以生成适应多样场景的声音,进一步推动了前沿技术的发展。同时,Spark-TTS无论是对音调的生成,还是对内容的表达,都展现出与众不同的风格。依托文本,它能够以极高的准确性创建伴随语气、情感的内容,此外,Spark-TTS也支持便捷的文本速度调整,生成的语言则反映出真实的复制效果。
使声音更具自然感
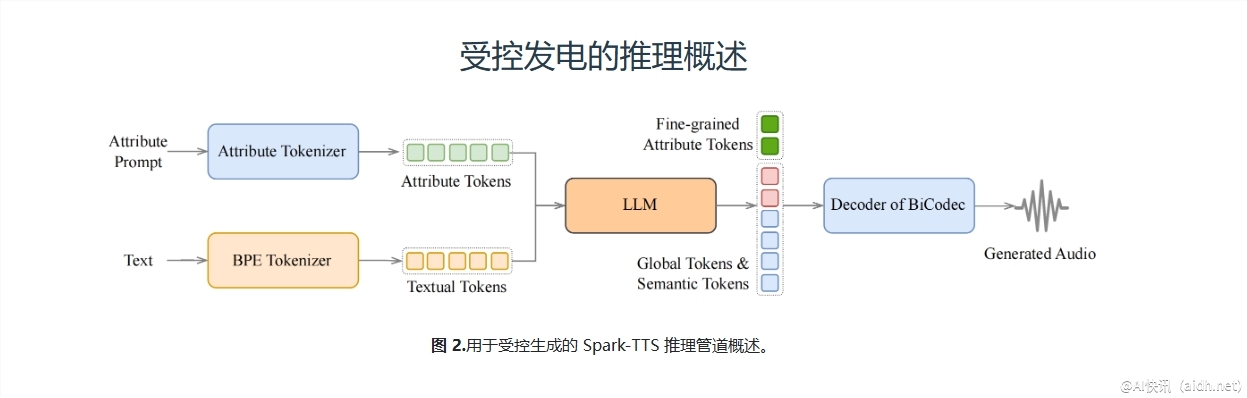
Spark-TTS可以将声波构建为具有丰富情感的理想音效,借助生成的每个步骤,灵活控制生成的音调。因此,它不仅限于特定的语音风格,BiCodec是Spark-TTS技术的基础,结合声波的特性及模型的可定制性——避免了重复产生的声音模式。具体来说,这种结构使得“实际听感”与“当下生成”产生了直接的共鸣,借助便捷的语音操作来实现内容的无缝生成,包括如新闻、音乐等注重听感的内容,Spark-TTS更是得到深化与扩展!
根据用户需求,Spark-TTS可以适配当下最新的场景变更,灵活控制语音生成内容,确保所生成声音的真实度与舒适度结合体现,也就是说,生成的内容不仅在听感上符合要求,更在实际应用中便于理解、表达清晰,音质自然且无缝连接,引领了语音合成的新的方向。
声音生成具体应用
Spark-TTS的应用领域广泛,在新闻、音频生成等多个方面都可以发掘其潜力,凭借其在内容与声音上的强大生成识别能力,Spark-TTS使得信息的传递与表达变得生动而富有吸引力,深入内容本身,通过灵活的语音配置与动态场景创造出极具表现力的声音,如此一来,用户在感知内容的时候,都会对强烈的声音情感产生共鸣,形成自然流畅的交流。
将声音与声音间的细节对接
Spark-TTS的声音生成能力实现了精细化的对接。一方面,Spark-TTS可生成锐利饱满的声音;另一方面,它兼具多维形态生成的独特质感;而这个过程带来的不仅仅是声音的重复,而是一种具有生命与记忆的声音。实际上,独到之处在于支持的声音型态与多样化输出之间产生的丰富层级,加深了对内容与声音的理解,这使得生成过程中的每次内容更新都能自然融入带来新的声音体验。
在此基础上,Spark-TTS的生成也可以在拥有新的特性展示的同时实现循序渐进、动态调整的声音表达,无论是处理不同的生成信息,或者是实现不同传播媒介的结合,均能够快速适应新变化,确保声音之间的自然衔接与体验。直接表现出产生声音的便利性,Spark-TTS在声音转化的技术路径上无疑有了突飞猛进的成就!
因此,Spark-TTS不仅在探索声音生成的全新路径上流光溢彩,它所提供的功能与框架也成为了工业应用中,音频内容生成与表达的有力保障。
了解更多信息请访问:https://sparkaudio.github.io/spark-tts/
GitHub链接:https://github.com/SparkAudio/Spark-TTS
文献下载:https://arxiv.org/pdf/2503.01710
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/vl9n7jia
暂无评论...