
摘要:
在计算机科学领域,将复杂结构的文档转化为规整的数据一直是一个具有挑战性的问题。传统方法要么通过复杂流程组合各种 […]
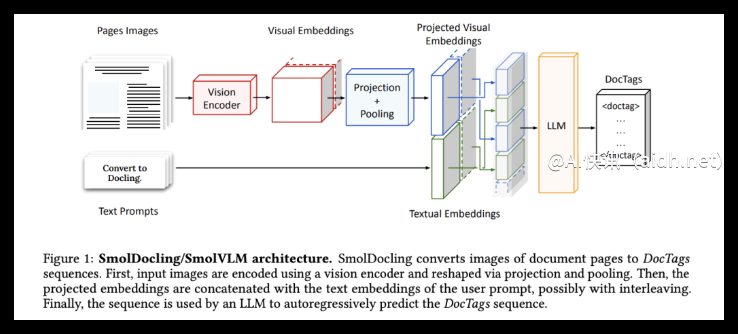
在计算机科学领域,将复杂结构的文档转化为规整的数据一直是一个具有挑战性的问题。传统方法要么通过复杂流程组合各种模型,要么采用庞大且资源密集的多模态模型,这些方法虽然看起来强大,但往往难以维护并且成本高昂。
然而,最近由IBM和Hugging Face联手推出的SmolDocling却以其独特之处引起了人们的关注。作为一款只有256M参数的开源视觉-语言模型(VLM),SmolDocling的目标非常明确,即端到端地解决多模态文档转换任务。
SmolDocling最突出的特点在于其小巧玲珑的体量和独特的技术。相比于那些数十亿、数百亿参数的大型模型,SmolDocling的256兆体积可以被视为模型界的“轻骑兵”,显著减少了计算复杂性和资源需求。此外,它能够通过单个模型处理整个页面,从而简化了传统方法中繁琐的处理流程。
除了体量小巧,SmolDocling还拥有独特的“武器”——DocTags。这种通用的标记格式能够以高度紧凑和清晰的方式精确捕捉页面元素、它们的结构和空间上下文,为机器准确理解文档的内在逻辑提供了便利。
总的来说,SmolDocling的发布代表着文档转换技术的重大突破。它不仅在性能测试中表现优异,还展现出了处理各种复杂文档元素的能力。由于其高效性和经济性,SmolDocling为企业处理海量复杂文档提供了一种新的解决方案。通过有针对性的训练和创新的数据增强,像DocTags这样的新型标记格式,SmolDocling不仅与大型基础模型竞争,而且在关键任务中还能够显著超越它们。
快讯中提到的AI工具

Hugging Face
机器学习和人工智能技术的平台
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/806sdref
暂无评论...


















