


自动形式化数学定理证明是人工智能在数学推理领域的重要应用之一。这类任务需要将数学命题和证明步骤转换为计算机可验证的代码,这不仅能够确保推理过程的绝对严谨性,还能构建可复用的数学知识库,为科学研究提供坚实的基础。
早在20世纪中叶,众多逻辑学家、数学家及人工智能开创者,如戴维斯与明斯基,便开始探索这一领域,其中以王浩与吴文俊等华人学者的贡献尤为显著。
近年来,借助大型语言模型(LLM)的能力,自动定理证明系统愈加依赖于复杂的蒙特卡洛树搜索(MCTS)或价值函数(Value Function)来指导其搜索过程。
然而,这些方法引入了额外的计算成本,并增加了系统的复杂性,导致在大规模推理任务中的可扩展性受到限制。
字节跳动豆包大模型团队推出的 BFS-Prover 则对这一传统范式提出了挑战。
作为一种更为简洁和轻量级但极具竞争力的自动定理证明系统,BFS-Prover 引入了三项关键技术:1)专家迭代(Expert Iteration)与自适应数据过滤,2)直接偏好优化(DPO)结合 Lean4 编译器反馈,3)在 BFS 中应用长度归一化。
根据结果显示,BFS-Prover 在形式化数学测试集 MiniF2F 上取得了 72.95% 的准确率,创造了新的领域记录。
这一结果首次证明,在合理的优化策略下,简单的 BFS 方法能够超越包括蒙特卡洛树搜索(MCTS)和价值函数(Value Function)在内的主流复杂搜索算法。
目前,相关论文成果已对外公开,模型也已开源,期待与相关研究者进行更深入的交流。
- BFS-Prover: Scalable Best-First Tree Search for LLM-based Automatic Theorem Proving
- 链接:https://arxiv.org/abs/2502.03438
- HuggingFace:https://huggingface.co/bytedance-research/BFS-Prover
Part1:主流方法蒙特卡洛树搜索和价值函数真的必要么?
在形式化数学证明领域,将抽象的数学概念转化为可以用计算机验证的严格形式,是一项具有挑战性的任务。
该过程要求每一步推理均符合严格的形式逻辑规则,并必须经过 Lean 证明助手的验证。
在自动形式化定理证明的过程中,计算机面临的核心挑战是——在庞大且高度结构化的证明空间中找到有效路径。这一难点与传统搜索问题有本质区别,具体现象如下:
- 搜索空间庞大:每一步推理可能存在数十甚至数百种策略选择;
- 动态变化的策略空间:与棋类游戏的固定规则不同,在数学定理证明中,每个状态下可用的策略集不断变化,且规模庞大且无明确界限;
- 反馈稀疏与延迟:在完成证明之前,系统很难获得有效的中间反馈;
- 开放式推理过程:缺乏明确的终止条件,证明尝试可能会无限延续;
现有的自动定理证明系统如 DeepSeek-Prover-V1.5、InternLM2.5-StepProver 和 HunyuanProver,主要依赖于复杂的蒙特卡洛树搜索(MCTS)和价值函数(Value Function)来解决上述问题。
这些类似 AlphaZero 算法框架在围棋等游戏中表现卓越,推动了强化学习的广泛应用。然而在自动定理证明领域,由于状态空间极为复杂以及缺乏明确的奖励信号,上述主流方法的效果并不理想。此外,复杂的搜索算法增加了计算成本和系统复杂性等问题。
Part2:化繁为简,用机器证明数学定理可以更简单
人类在面临问题时,往往优先采用最有可能解决问题的方法。最优先树搜索(Best-First Tree Search,BFS)正是如此。
BFS 是一种通过在“树”或“图”中搜索节点的算法。其核心思想是根据某种启发式函数评估每个节点的优先级,并根据优先级访问节点。该方法常用于解决约束满足问题和组合优化问题,特别是在需要快速寻找近似最优解的情况下。ion>
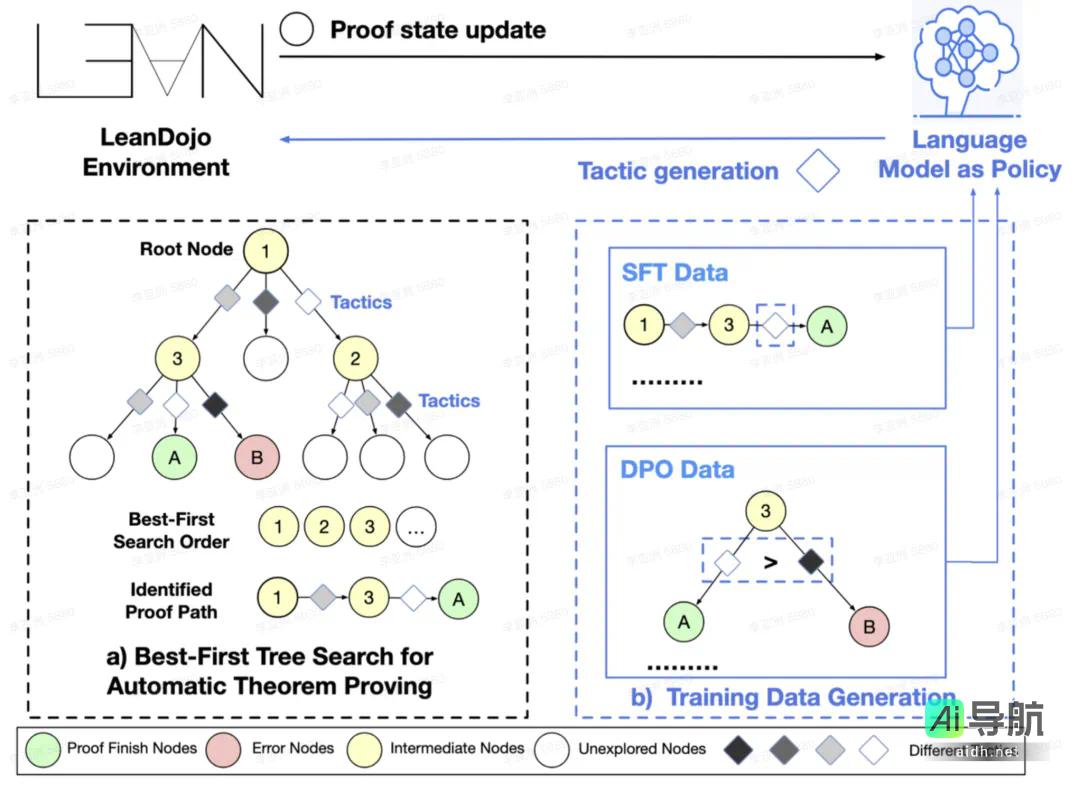
右侧部分展现了训练数据的生成过程,其中包括用于监督微调的 SFT 数据(成功证明路径上的状态与策略的配对)以及用于直接偏好优化的 DPO 数据(从相同状态出发的正确策略与错误策略的对比)。
左侧部分展示了 BFS 机制的运作,系统通过与 LeanDojo 环境和 Lean4 的交互,从根节点开始依照优先级顺序(1→2→3…)探索证明路径,直到找到证明完成节点(绿色 A 点)。
整个系统形成了一个闭环:大型语言模型(LLM)生成策略 → LeanDojo 执行策略 → 获取反馈 → 生成训练数据 → 优化 LLM → 再次生成策略,从而实现了持续改进的专家迭代机制。
 团队认为,BFS-Prover 系统的设计不仅在性能上超过了复杂的蒙特卡洛树搜索(MCTS)和价值函数方法,还保持了简洁的架构和高效的计算性能。其技术特征包括:
团队认为,BFS-Prover 系统的设计不仅在性能上超过了复杂的蒙特卡洛树搜索(MCTS)和价值函数方法,还保持了简洁的架构和高效的计算性能。其技术特征包括:
- 兼具深度思考与简洁证明能力
BFS-Prover 采用了一种专家迭代框架,通过多轮迭代逐步增强 LLM 的能力。在每一轮迭代中,系统首先使用确定性的束搜索(Beam Search)方法筛选掉容易解决的定理,将这些“简单问题”排除在训练数据之外,然后集中精力应对“复杂问题”。
这一数据过滤机制颇具创新性,确保训练数据逐步倾向于更具挑战性的定理证明任务,从而使 LLM 学会更为多样的证明策略。
如下图的实验数据显示,随着迭代的推进,系统所发现的证明平均长度逐渐增加,覆盖面也更为广泛,进一步验证了这一方法的有效性。 与此同时,LLM 生成的策略分布也发生了显著变化。
与此同时,LLM 生成的策略分布也发生了显著变化。
如下图所示,经过多轮迭代,模型生成的策略长度分布出现了明显的变化:极短策略(1-10 个 token)的比例有所下降,而中等长度策略(11-50 个 token)的比例则有所增加。
这一分布变化说明了 LLM 的“深度思考能力”在增强,从而避免了强化学习中常见的分布坍缩问题,并逐步掌握了更复杂和信息量更大的证明策略。
同时,模型生成简洁策略的能力依然得以保持。这种策略多样性的生成能力对于有效的定理证明至关重要,因为不同的证明状态需要不同复杂度的策略,包括从简单的项重写到复杂的代数操作等多种情况。
- 从过程中总结“错误证明步骤”,提升证明能力
在证明搜索的过程中,当 LLM 生成的某些策略导致 Lean4 编译器错误时,系统会将这些无效策略与成功策略相结合,以形成负反馈信号。
BFS-Prover 创新性地依赖于这些数据,以直接偏好优化(DPO)技术对策略 LLM 进行优化。这一方法显著提升了模型识别有效策略的能力,并优化了策略分布,提高了 BFS 的采样效率。
如下图的实验结果表明,在不同的计算量级下,经过 DPO 优化的模型均取得了显著的性能提升,验证了负面信号在定理证明中的重要作用。
- 克服对深度推理的压制,攻克高难度定理证明
为了应对 BFS 对深度推理路径的固有压制,BFS-Prover 系统引入了可调节的长度归一化评分函数: 其中,L 表示路径长度,α 是可调节的长度归一化参数。通过适当调整 α 值,系统能够在高概率路径的利用与深层路径的探索之间取得平衡,从而使 BFS 更有效地探索长链证明。
其中,L 表示路径长度,α 是可调节的长度归一化参数。通过适当调整 α 值,系统能够在高概率路径的利用与深层路径的探索之间取得平衡,从而使 BFS 更有效地探索长链证明。
第三部分:BFS-Prover 在 MiniF2F 测试集上取得新的 SOTA
团队对 BFS-Prover 在 MiniF2F 测试集上进行了全面评估。该测试集是形式化数学领域公认的基准,包含高难度的竞赛级数学问题,被广泛应用于自动定理证明系统能力的衡量。
- 超越现有最佳系统
在与领先定理证明系统的对比中,BFS-Prover 显示出显著的优势。
在固定策略生成的计算量(2048×2×600 次推理调用)下,BFS-Prover 实现了 70.83% 的准确率,超越了所有现有系统,包括采用价值函数的 InternLM2.5-StepProver(65.9%)、HunyuanProver(68.4%)以及基于 MCTS 的 DeepSeek-Prover-V1.5(63.5%)。
通过累积评估,BFS-Prover 的准确率进一步提升至 72.95%,成为形式化定理证明领域的新标准。>
这些证明展示了该系统在处理复杂数学推理方面的卓越能力,涉及数论、不等式及几何关系等多个领域。
例如,在针对 imo_1983_p6 中的不等式问题时,BFS-Prover 能够生成一种简洁而优雅的形式化证明:
 总结
总结团队认为,BFS-Prover 的成功背后蕴藏着自动定理证明领域的一项重要启示:简洁算法与精心设计的优化策略相结合,同样能够推动 AI4Math 领域的边界扩展。
随着大型语言模型能力的不断提升,BFS-Prover 所开创的高效、简洁路线有望进一步推动自动形式化定理证明领域的发展,为数学研究提供更为强大的自动化工具支持。
展望未来,团队计划继续增强 BFS 方法在处理更为复杂数学问题时的能力,特别是面向本科和研究生级别的数学定理。同时,团队还将基于推理模型及其他前沿方向,持续挖掘模型的潜力。
团队期望通过不断优化数据和训练策略,为数学研究提供强有力的辅助,助力加速数学发现过程,并最终实现人机协作解决前沿数学挑战的愿景。
文章中提到的AI工具
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点



暂无评论...