



摘要:
最近,谷歌、卡内基梅隆大学以及 MultiOn 的研究团队共同发布了关于合成数据在大型模型训练中的新研究。根据 […]
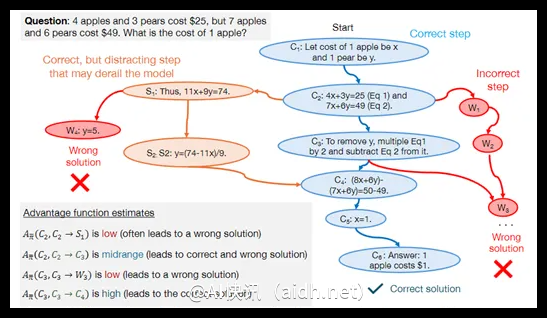
最近,谷歌、卡内基梅隆大学以及 MultiOn 的研究团队共同发布了关于合成数据在大型模型训练中的新研究。根据 AI 研究机构 Epoch AI 的报告,目前公开可用的高质量文本训练数据约为300万亿个 token,但随着类似 ChatGPT 的大型模型迅速发展,对训练数据的需求正以指数级增长。预计在2026年前,这些数据将会用尽,因此合成数据正在逐渐成为重要的替代解决方案。
研究人员探索了两种主要类型的合成数据:正面数据和负面数据。正面数据是指由高性能大型模型(如 GPT-4 和 Gemini1.5Pro)生成的正确问题解决方案,为模型提供了解决数学问题的学习示例。然而,仅依赖正面数据进行训练存在一定局限性。首先,这种方法可能无法深入揭示问题解决过程中的内在逻辑,模型可能只是通过模式匹配学习而缺乏真正的理解。其次,随着训练数据的增加,模型可能会学习到一些偶然的错误关联,导致在处理新问题时的泛化能力下降。
因此,研究人员引入了负面数据类型。这些数据包含被验证为错误的解题步骤,能够帮助模型识别并避免错误,增强其逻辑推理能力。尽管利用负面数据面临一定挑战,因为错误步骤可能带有误导性信息,但通过直接偏好优化(DPO)方法进行优化,研究人员成功使模型从错误中学习,并强调每一步解题的重要性。
DPO 方法为每个解题步骤分配一个优势值,反映该步骤相对于理想解法的价值。研究表明,高优势值步骤是正确解题的关键,而低优势值步骤可能意味着模型推理中存在问题。通过这些优势值,模型能够在强化学习框架下动态调整策略,更有效地学习和改进合成数据。
为验证合成数据的效果,研究团队在 GSM8K 和 MATH 数据集上对 DeepSeek-Math-7B、LLama2-7B 等模型进行了综合测试。结果显示,经过正面和负面合成数据预训练的大型模型,在数学推理任务中的性能提升了八倍。这一研究成果展示了合成数据在提升大型模型逻辑推理能力方面的巨大潜力。
快讯中提到的AI工具
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/urmtmier
暂无评论...
















