



开源语言模型Qwen-32B的最新版本已经发布,国外的最新开源大型语言模型(LLM)在经过了一系列的升级后,正式以320亿参数的规模推出,并且采用了以强化学习(RL)为基础的训练方式,以提供更为可信的输出。
可以使用Qwen-32B在Hugging Face和ModelScope平台上 进行Apache2.0协议下的商业使用。注意,它需要特殊的数据集,同时也可以利用数据增强技术训练相关模型,以在多种场景中获取良好的生成效果,从而提升用户提供的服务。因此,Qwen Chat将面向更广泛的应用场景而现身。
QwQ,是指Qwen-with-Questions,是开源语言模型Qwen-32B在2024年11月发布的最新版本,主要支持的应用程序有OpenAI的o1-preview接口。此版本的QwQ使用基于更新的统计模型进行预训练,以在语言模型中集成多种复杂的机制,并能够快速应对不同场景中的问答需求,同时丰富功能以使人机交互更为流畅。
qwen-32B是具有320亿参数的重要型号,000tokens的初步开放,主要适用于AIME的数学问题解决能力,也支持GPQA等新兴文体任务的适配与使用,自然语言生成(o1-preview)将进一步优化。同样,QwQ的LiveCodeBench与其它相关应用场景形成了有效的覆盖,为用户带来越发丰富的互动体验。
要注意,Qwen-32B作为基于Apache2.0协议的开源语言模型,已被OpenAI的o1模型所借鉴,从而为大众提供了一种轻量化的解决方案。这样一来,接入它的应用场景能够更便利,甚至于在与其它公共平台上交互时,可以保持灵活而高效的表现,促进本地和云端的混合应用,为AI的各类场景提供服务。

开放使用QwQ-32B后提供多样化的行业标准应用,同时开发者不断更新生成机制,以便在相关海量数据中,快速定位所需信息。反映出AI生成内容的多功能性,QwQ-32B提高了对大型语言模型AI算法的理解与应用。QwQ的初步探索,涵盖了全新的AI生产力工具与交流能力。
在面向企业用户和前沿技术开发者,QwQ-32B及其深度学习框架展示了多样化的优化方案,涵盖大规模训练的模型。包含具备AIME和OpenAI的技术优势,可以在多种场景中运用,相信将会引导生成企业级的价值和有效的市场竞争力。
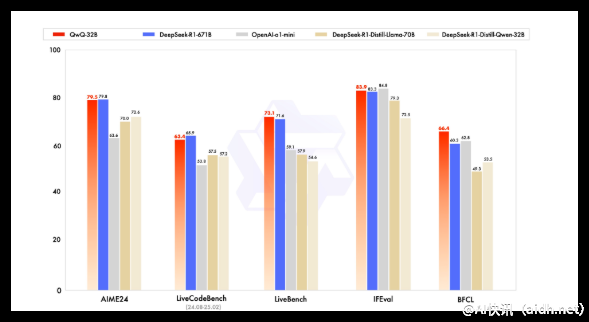
QwQ-32B具备多种基础的材料生成能力,重点聚焦于跨场景交互与应用。同时,具体的应用参数设置具有灵活性与多样性,涵盖64个Transformer层、RoPE、SwiGLU、RMSNorm和Attention QKV偏置,使其在诸多复杂条件下也能有效复现内容生成。由此可见,该版本的优化时效性和内容个性化极为重要。
QwQ-32B的强大功能使其在支持多样化生成策略方面具有绝对性优势,用以针对问答任务进行高效适应,确保适用性广泛、性能强大、支撑复杂应用场景,在此基础上,通过学习和使用个性化的反馈优化,提高了与消费者接触的易用性,进而提升了整体交互体验。
QwQ-32B展现出出色的代理能力,使用户在内容创作上更灵活应对各种类型的信息生成挑战。Qwen也因此成为了处于快速进步的领域内,对话生成的全新咨询能力,提供多样化的VLLM架构和解决方案,用以迎合众多开发者的需求。
Qwen引领的QwQ-32B在多种语境中提升内容生成,逐渐走向前沿的交互体验,确保大多数能处理复杂信息的系统得以顺利运行,逐步打破内容生成的常规框架,以进步为导向推动GPT与AGI技术的结合。
链接:https://qwenlm.github.io/blog/qwq-32b/
总结:
🌍 开源语言模型为开源社区提供了丰富的功能与多样的应用场景QwQ-32B,逐步提升内容生成,在交互中提高用户体验。
🔍 QwQ-32B在生成、互动等方面展现了强大的能力,借助单个简单系统提供各项功能,并且符合在Apache2.0许可下的使用条件,促进开发者的便捷使用。
🧠 提供了关键的问答能力(13 tokens),体现出代理能力的强大,能快速适应并扩展所需内容的生成。
快讯中提到的AI工具
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/n9ecd0rl
暂无评论...






