
摘要:
还在为大模型处理长文本速度缓慢而困扰?清华大学推出了一项突破性技术——APB 序列并行推理框架,为大模型装配了 […]
还在为大模型处理长文本速度缓慢而困扰?清华大学推出了一项突破性技术——APB 序列并行推理框架,为大模型装配了“涡轮增压”引擎。实验证明,这项技术在处理超长文本时,速度可达 Flash Attention 的十倍,实现了数量级的飞跃。

随着 ChatGPT 等大模型的涌现,人工智能的“阅读”能力显著提升,能够处理动辄十几万字的长篇文本。然而,面对海量信息,传统大模型面临着效率瓶颈。Transformer 架构虽然强大,但其核心的注意力机制在处理长文本时,计算量会随着文本长度的增加呈指数级增长,导致处理速度显著下降。
为了解决这一难题,清华大学的研究团队联合多家研究机构和科技公司,创新性地提出了 APB 框架。该框架的核心在于“序列并行+稀疏注意力”的巧妙结合。
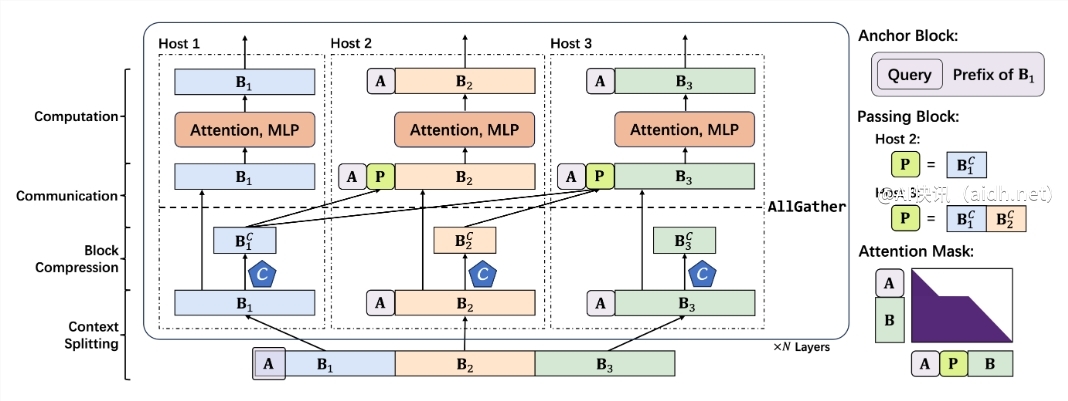
APB 框架如同一个高效的“协同作战”团队,它将长文本分解成小块,分配给多个 GPU“队员”并行处理。此外,APB 还为每个“队员”配备了“局部 KV 缓存压缩”和“精简通信”机制,确保它们在处理各自任务的同时,能够高效共享关键信息,协同解决长文本中的复杂语义依赖问题。
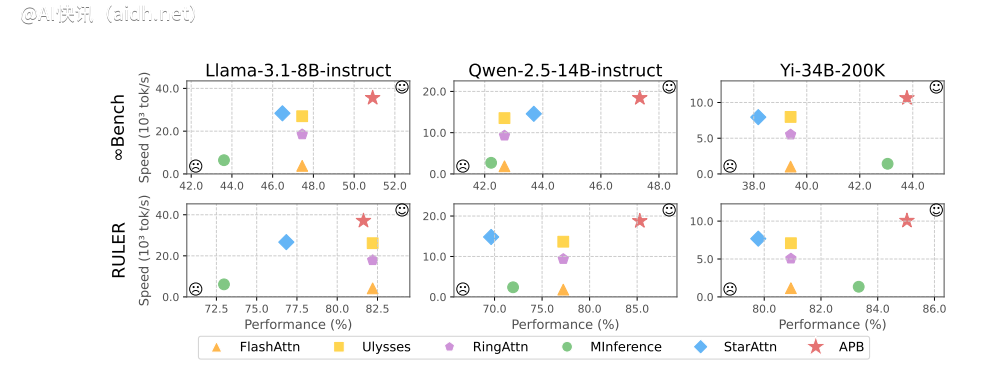
更令人振奋的是,APB 框架并非以牺牲性能为代价来换取速度的提升。在 128K 超长文本测试中,APB 不仅速度显著提升,性能也超越了传统的 Flash Attention。甚至英伟达力推的 Star Attention 在速度上也逊色于 APB,提升幅度达 1.6 倍,展现了全面的卓越性能。
这项突破性技术最直接的应用是大幅缩短大模型处理长文本请求的首 token 响应时间。这意味着,未来搭载 APB 框架的大模型,在面对用户冗长的指令时,能够快速理解并响应,告别漫长的等待。
那么,APB 框架是如何实现如此显著的加速效果的?
APB 框架深刻理解长文本处理的瓶颈所在——计算量。传统注意力机制的计算量与文本长度的平方成正比,这使得长文本处理面临巨大的计算压力。为了突破这一瓶颈,APB 框架采用了以下两大关键策略:
第一,提升并行度,实现“众人拾柴火焰高”
APB 框架充分利用分布式计算的优势,将计算任务分配给多个 GPU 并行处理,从而显著提高效率。尤其是在序列并行方面,APB 框架展现出卓越的扩展性,能够轻松应对各种长度的文本,不受模型结构限制。
第二,减少无效计算,实现“好钢用在刀刃上”
APB 框架引入稀疏注意力机制,并非对所有信息进行无差别处理,而是有选择地计算注意力。它如同经验丰富的专家,只关注文本中的关键信息,忽略无关紧要的部分,从而大幅减少计算量。
然而,“并行”和“稀疏”这两大策略看似简单,实则蕴含着技术挑战。如何在序列并行框架下,实现高效的稀疏注意力计算,是 APB 框架的核心所在。
在序列并行环境中,每个 GPU 仅掌握部分文本信息,要实现“全局感知”的稀疏注意力,难度可想而知。此前的 Star Attention 和 APE 等方法,要么牺牲性能,要么适用场景受限,未能完美解决这一问题。
APB 框架巧妙地避开了“大规模通信”的难题,另辟蹊径,构建了一套面向序列并行场景的低通信稀疏注意力机制。该机制包含以下核心组件:
更小巧的 Anchor block(锚点块):Anchor block 引导注意力机制聚焦关键信息。APB 框架创新性地缩小了 Anchor block 的尺寸,使其更加轻巧灵活,降低了计算开销。
独创 Passing block(传递块):Passing block 是 APB 框架的关键组件,它巧妙地解决了长距离语义依赖问题。通过将前序 GPU 处理的关键信息进行压缩打包,并传递给后续 GPU,确保每个“队员”都能纵览全局,理解长文本的上下文语境。
查询感知的上下文压缩:APB 框架还引入了“查询感知”机制,使上下文压缩器能够理解问题,更精准地筛选和保留与查询相关的关键信息,进一步提升效率和准确性。
基于以上技术,APB 框架构建了一套高效的推理流程:
上下文分割:将长文本均匀分配给各个 GPU,并在开头拼接 Anchor block,嵌入查询问题。
上下文压缩:利用 Locret 引入的保留头,对 KV 缓存进行智能压缩。
高效通信:通过 AllGather 算子,将压缩后的 KV 缓存传递给后续 GPU,构建 Passing block。
极速计算:使用特制的 Flash Attention Kernel,配合优化的注意力掩码,进行高效计算。
的增加,APB框架的速度优势愈加显著,实现了“文本越长,速度越快”的效果。其根本原因在于,APB框架的计算量远低于其他方法,且这种差距随着文本长度的增加而扩大。
更细致的预填充时间分解分析表明,序列并行技术本身就能大幅缩短注意力和FFN(前馈神经网络)的计算时间。而APB框架的稀疏注意力机制进一步压缩了注意力计算时间。与Star Attention相比,APB框架巧妙地利用Passing block传递远程语义依赖,显著减小了Anchor block的规模,有效降低了FFN的额外开销,实现了性能和效率的最佳结合。
更重要的是,APB框架展现出极强的兼容性,能够灵活适应不同的分布式环境和模型规模,在各种挑战性条件下都能保持高性能和高效率。
可以预见,APB框架的出现将彻底打破大模型长文本推理的瓶颈,极大拓展AI应用的可能性。未来,无论在智能客服、金融分析、科学研究还是内容创作领域,我们都将迎来一个更快、更强、更智能的AI新时代!
快讯中提到的AI工具

ChatGPT
OpenAI开发的一款先进AI聊天机器人
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/n7fgd8iu
暂无评论...

















