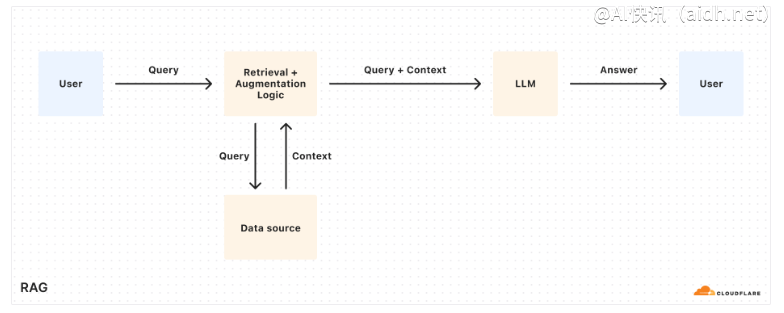
在检索增强生成(RAG)领域,提高长上下文语言模型的性能至关重要。Nvidia AI 的一项创新——ChatQA2 模型,旨在解决这一挑战,它代表了一种有前景的解决方案。ChatQA2 基于先进的 Llama3 模型,在处理长篇幅的上下文信息方面表现出色,能够有效地进行知识检索和复杂推理,从而显著提升性能。
关键优势: ChatQA2 能够处理高达 128K tokens 的上下文窗口,这使得它在处理需要深度理解和长期记忆的任务时更加强大,可以更好地进行信息检索、RAG 应用以及其他语言任务。该模型特别擅长处理超过 10K tokens 的超长上下文,能够保持对上下文的准确理解和连贯性。
性能表现:ChatQA2 的设计目标是尽可能提升长上下文处理能力。该模型成功地将 Llama3-70B 的上下文窗口从 8K tokens 扩展到了惊人的 128K tokens。值得一提的是,扩展上下文窗口的同时,该模型仍然能够保持卓越的检索和推理性能。
基准测试: 在 InfiniteBench 基准测试中,ChatQA2 在各种长上下文任务上展现出了卓越的性能,甚至超越了 GPT-4-Turbo-2024-0409 等领先模型,尤其在 RAG 相关的检索任务中表现突出。这些结果表明 ChatQA2 在处理长篇上下文和复杂推理方面具有显著优势。
实际应用:ChatQA2 通过优化 RAG 流程,显著提升了长上下文处理能力,从而增强了语言模型的知识整合和推理能力。这种改进使得模型在处理需要全面理解上下文的任务时更加有效,例如信息检索和问答等。
总而言之,ChatQA2 在扩展上下文窗口和提升性能方面都超越了 GPT-4-Turbo 模型,为长上下文语言模型和 RAG 应用带来了显著的进步。该模型能够更有效地处理复杂的推理和知识密集型任务,为未来的语言模型发展方向提供了新的思路,并在信息检索领域展现出巨大潜力。
论文链接:https://arxiv.org/abs/2407.14482
快讯中提到的AI工具

GPT-4
OpenAI 发布的最新一代语言模型
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/klgccn8h
暂无评论...