近日,Firecrawl 推出了全新的功能——LLMs.txt 生成器接口(Alpha 版)。该功能旨在协助用户将任意网站的内容转换为清晰的文本文件,以便于大语言模型(LLM)的训练。用户只需提供目标网站的 URL,Firecrawl 将自动抓取该网站及其链接页面,生成两种格式的文本文件:llms.txt 和 llms-full.txt,以便利后续的数据分析与训练。
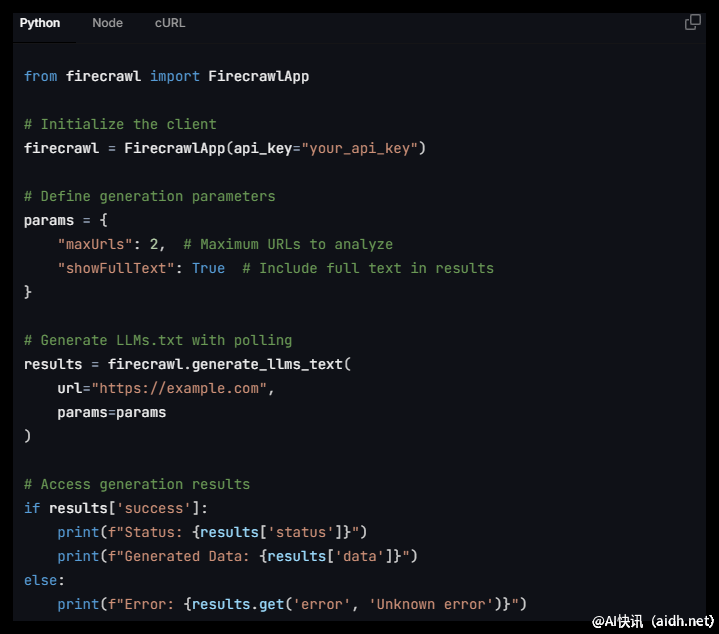
该生成器的工作流程相对简明。用户仅需输入一个网址,系统便会自动爬取相应网站的内容,并提取出整洁且富有意义的文本信息。生成的文件分为两种类型:llms.txt 提供了对网站内容的精练总结,包含关键信息,而 llms-full.txt 则提供更为详尽的完整文本内容,适合那些需要深入分析的用户。
在使用过程中,用户可设置一些关键参数。首先是“url”,该参数指定希望生成 LLMs.txt 文件的网址。用户还可以选择“maxUrls”参数,以控制最大爬取的页面数量,范围在 1 到 100 之间,默认为 10。此外,用户还可以选择是否生成 llms-full.txt,默认设置为不生成。
需要指出的是,LLMs.txt 生成器的工作为异步进行,用户可以发起请求并实时监控生成状态。系统会提供状态更新信息,例如“正在进行中”或“已完成”,以便用户随时掌握进度。
然而,由于该功能目前处于 Alpha 阶段,仍存在一些已知限制。首先,功能仅支持处理公开可访问的页面,无法对登录保护或付费墙内容进行处理。其次,在 Alpha 阶段,处理的网站数量上限设定为 5000 个 URL。此外,作为一项 Alpha 特性,输出格式和处理流程可能会根据用户反馈而进行调整。
在计费方面,使用 LLMs.txt 生成器的费用基于处理的 URL 数量,基本费用为每处理一个 URL 消耗 1 个积分。用户可以通过设置 maxUrls 参数来控制费用。
入口: https://docs.firecrawl.dev/features/alpha/llmstxt
划重点:
🌐 提供网站 URL,即可快速生成适用于 LLM 的文本文件。
📝 生成两种文本格式,以满足不同用户的需求。
🔒 仅支持公开页面处理,并且在 Alpha 阶段存在数量限制。
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/f7lso705
暂无评论...