人工智能领域正经历着大语言模型(LLM)的飞速发展。近日,卡内基梅隆大学(CMU)与 HuggingFace 的研究人员联合推出了一种名为 “元强化微调”(Meta Reinforcement Fine-Tuning,简称 MRT)的创新方法。该方法的核心在于优化大语言模型在测试阶段的计算效率,尤其是在处理复杂的推理问题时,其优越性更为显著。
既有研究表明,现有的大语言模型在推理过程中常常消耗过量的计算资源。MRT 旨在使模型在既定的计算预算范围内,实现更高效的答案检索。该方法将大语言模型的输出分解为多个片段,从而在探索与利用之间达成平衡。通过对训练数据的精细化学习,MRT 能够使模型在面临未知难题时,既能充分利用已知信息,又能积极探索新的解题策略。
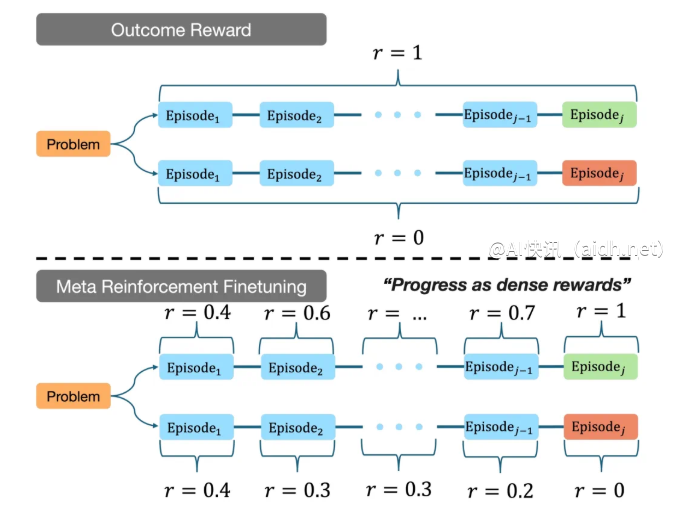
在实验中,CMU 团队的研究结果显示,经过 MRT 微调后的模型在多个推理基准测试中均取得了显著的性能提升。与传统的结果奖励强化学习(GRPO)方法相比,MRT 的准确率提升了2至3倍,同时 token 使用效率也提升了1.5倍。这意味着,MRT 不仅能够提高模型的推理能力,还能有效降低计算资源的消耗,从而在实际应用中展现出更大的优势。
此外,研究人员还提出了有效评估现有推理模型性能的方法,为未来的研究奠定了坚实的基础。该研究成果不仅展示了 MRT 的巨大潜力,也为大语言模型在更广泛的复杂应用场景中的应用指明了方向。
通过这项创新,CMU 与 HuggingFace 的研究团队无疑推动了人工智能技术的发展前沿,赋予机器更强大的推理能力,并为实现更智能化的应用奠定了坚实的基础。
项目地址:https://cohenqu.github.io/mrt.github.io/
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/29jgbf74
暂无评论...