
摘要:
百度AI于3月11日开源了全新表格识别解决方案PP-TableMagic,标志着表格结构化信息提取技术取得重大 […]
百度AI于3月11日开源了全新表格识别解决方案PP-TableMagic,标志着表格结构化信息提取技术取得重大进展。该方案旨在克服传统技术在复杂场景下的局限性,通过创新的多模型组网架构实现高精度端到端表格识别,并支持全场景高定制化模型微调。
当前,大量关键表格数据以非结构化形式存在,例如扫描文档中的统计图表和PDF文件中的财务报表,阻碍了自动化处理。表格识别技术因此成为文档智能理解和数据分析的关键环节。然而,传统通用模型在处理复杂表格格式时往往表现欠佳,难以满足各种应用场景的特定需求。为此,百度飞桨团队推出了PP-TableMagic,采用“表格分类+表格结构识别+单元格检测”的多模型串联组网方案,显著提升了表格识别的准确性和适应性。
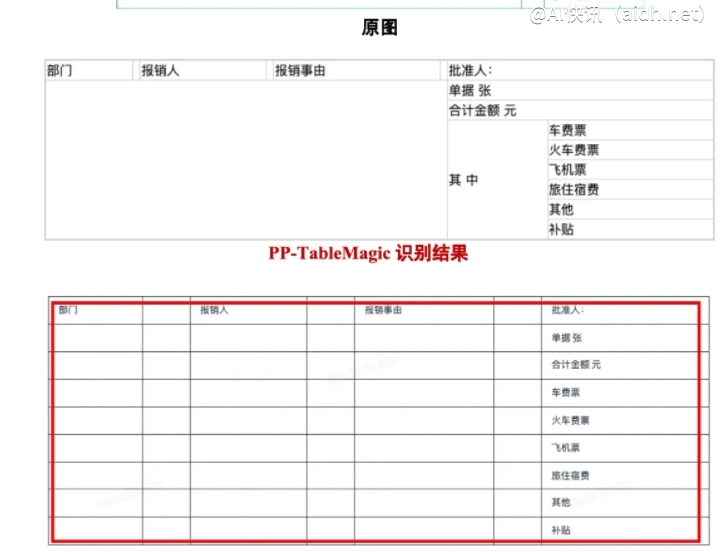
PP-TableMagic的核心优势在于其创新的架构设计。该方案采用双流架构,将表格分为有线表和无线表两类,并将端到端表格识别任务分解为单元格检测和表格结构识别两个子任务。最终,通过自优化结果融合算法生成完整的HTML表格预测结果。其中,飞桨团队自主研发的轻量级表格分类模型PP-LCNet_x1_0_table_cls能够高精度地对有线表和无线表进行分类;业界首个开源表格单元格检测模型RT-DETR-L_table_cell_det实现了对各种类型表格单元格的精准定位;而全新表格结构识别模型SLANeXt则在表格HTML结构解析方面表现出色,相比前代模型SLANet和SLANet_plus,SLANeXt采用更强大的特征表征能力的Vary-ViT-B作为视觉编码器,进一步提升了表格结构识别的准确性。
PP-TableMagic不仅能够直接处理表格,还能通过定制化模型微调满足不同场景的需求。与传统端到端模型的微调相比,PP-TableMagic的多模型组网架构允许用户仅对关键模型进行微调,从而避免了性能的相互制约,并减少了数据标注的工作量。此外,资深开发者还可以进行分支级调整,针对特定类型的表格数据进行优化,进一步提升整体识别能力。
为方便用户使用,PP-TableMagic提供详细的安装指南和使用教程。用户可通过PaddleX提供的Python API轻松调用模型,进行表格识别和结果导出。此外,PP-TableMagic还支持高性能推理、服务化部署以及端侧部署,以满足不同用户的需求。百度飞桨团队计划于3月13日举办线上课程,深入讲解PP-TableMagic的技术细节,并开设产业场景实战营,指导用户体验从数据准备到模型部署的完整开发流程。
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/526fldfk
暂无评论...


















