摘要:
2024年12月26日,中国人工智能初创公司深势科技发布了其最新一代的大规模语言模型DeepSeek-V3,标 […]

2024年12月26日,中国人工智能初创公司深势科技发布了其最新一代的大规模语言模型DeepSeek-V3,标志着该公司在推进通用人工智能技术领域迈出了重要一步。
DeepSeek-V3包含6710亿个参数,采用了混合专家架构(MoE),能够实现高效的推理和知识检索。据DeepSeek官方介绍,这一新模型在性能上已超越Meta的Llama3 1-405B,并可与Anthropic和OpenAI的顶级模型相媲美。
DeepSeek-V3的设计目标是支持人工智能到通用人工智能的过渡。深势科技,这家由High-Flyer Capital Management支持的公司,致力于通过开发通用人工智能(AGI)基础设施,推动科学和产业的进步,从而解决现实世界的复杂问题。
DeepSeek-V3的关键技术创新包括:
相对于DeepSeek-V2,该模型在模型架构、多语言理解(MLA)以及DeepSeekMoE的混合专家系统中进行了优化,从而提升了整体性能。
在上下文处理方面,DeepSeek-V3实现了显著提升:通过创新的多阶段训练范式(MTP),该模型能够在训练的不同阶段有效地处理不同长度的上下文,从而提升了长上下文的推理能力,能够处理长达60万个token。
在训练策略上,DeepSeek-V3使用了14.8万亿token的多样化数据集进行训练,并通过有监督微调(SFT)和强化学习(RL)等技术,使其在各种任务中表现出色,并确保模型在实际应用中保持可靠性。
在训练基础设施方面,DeepSeek利用了张量并行和流水线并行的组合,以及FP8数据类型支持和DualPipe技术,实现了高效的模型训练。DeepSeek-V3的初始训练阶段使用了2788个H800 GPU,耗时约557个计算日,充分展示了其在算力资源方面的投入。
DeepSeek-V3在多个基准测试中展现出卓越的性能。在语言理解方面,其表现优于包括GPT-4o在内的其他模型,尤其是在诸如SimpleQA和FRAMES等复杂推理任务上,DeepSeek-V3的性能提升显著(DeepSeek-V3的相对改进为24.9%到73.3%,而OpenAI模型的相对改进为38.2%到80.5%)。此外,DeepSeek-V3在数学推理方面也表现出色,在Math-500测试中达到了90.2%的准确率,超过了Qwen的80%的得分。
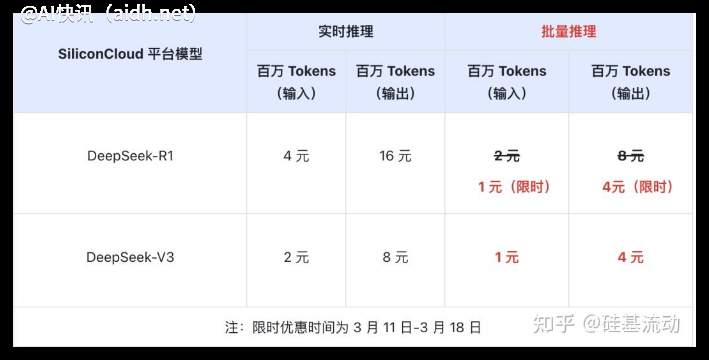
目前,DeepSeek-V3的模型权重已在GitHub上以MIT许可证发布,方便研究人员和开发者使用。同时,用户还可以通过DeepSeek Chat(类似于ChatGPT的界面)体验该模型,并利用API进行应用开发。DeepSeek还提供了DeepSeek-V2的商业API,价格从每百万token的输入0.27美元(输出为每百万token 0.07美元)到每百万token的上下文窗口1.10美元不等。
要点总结:
✨ DeepSeek-V3的发布,旨在挑战Llama和Qwen等领先模型。
🔥 模型参数高达671B,采用混合专家架构,性能卓越。
🚀 通过创新技术,显著提升了长上下文处理能力。
💡 提供商业友好的API,支持广泛的AI应用开发。
快讯中提到的AI工具

DeepSeek
深度求索:引领未来人工智能技术的探索与创新

GPT-4o
OpenAI 最新的旗舰模型

GPT-4
OpenAI 发布的最新一代语言模型

OpenAI
致力于创造对全人类有益的安全 AGI

ChatGPT
OpenAI开发的一款先进AI聊天机器人
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/4jpm1c0p
暂无评论...