摘要:
近日,DeepSeek推出了其最新一代大型语言模型DeepSeek-V3,此模型在性能方面实现了显著的提升。与 […]

近日,DeepSeek推出了其最新一代大型语言模型DeepSeek-V3,此模型在性能方面实现了显著的提升。与传统的MoE(混合专家)架构有所不同,该模型在推理过程中能够更加高效地利用所有可用的参数,从而确保卓越的响应速度和精确性。
在模型规模上,DeepSeek-V3拥有高达6710亿的参数总量,其中激活参数达到370亿。值得一提的是,该模型支持高达14.8万token的上下文窗口,为处理更长篇幅的文本提供了可能。经过优化,该模型的首字生成延迟仅为3秒,后续每个token的生成时间约为60毫秒,从而实现了快速且流畅的交互体验。
在各项基准测试中,DeepSeek-V3展现出了卓越的性能。它不仅超越了Qwen2.5-72B和Llama-3.1-405B等其他大型语言模型,还在某些能力上与GPT-4及Claude-3.5-Sonnet等顶级模型相媲美。这意味着该模型在理解和生成文本方面具备强大的实力,能够胜任各种复杂的任务。
更为重要的是,DeepSeek-V3在成本效益方面也表现出色。在进行模型推理时,只需占用两张GPU卡,便能实现高达557.6 TFLOPs的算力利用率。这种高效的资源利用方式降低了部署和运行成本,为更广泛的应用提供了可能性。正如OpenAI研究员Karpathy所指出的那样,DeepSeek-V3仅使用280张GPU卡进行训练,便能达到与使用数千张GPU卡训练的Llama3相媲美的性能水平,这无疑是一项令人瞩目的成就。
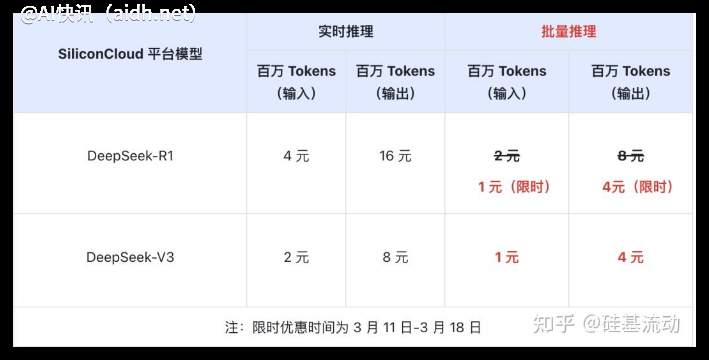
在API定价方面,DeepSeek-V3也极具竞争力。其输入价格在每百万tokens 0.5-2美元之间,输出价格为每百万tokens 8美元,并且提供了高达10美元的免费试用额度。相比之下,GPT-4的同等服务价格高达每百万tokens 140美元,成本优势显而易见。
总而言之,DeepSeek-V3的发布标志着国产AI技术取得了新的突破,为人工智能领域的发展注入了新的活力。它不仅具备强大的性能和高效的资源利用率,还提供了极具竞争力的价格,有望在各种实际应用中发挥重要作用,推动AI技术的普及和发展。
快讯中提到的AI工具

DeepSeek
深度求索:引领未来人工智能技术的探索与创新

Claude
由Anthropic公司开发的下一代人工智能AI助手

GPT-4
OpenAI 发布的最新一代语言模型

OpenAI
致力于创造对全人类有益的安全 AGI
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/mvknnr2t
暂无评论...