



摘要:
最新的独立评估显示,Meta所推出的Llama4模型中的Maverick和Scout在标准测试中表现出色,但在 […]
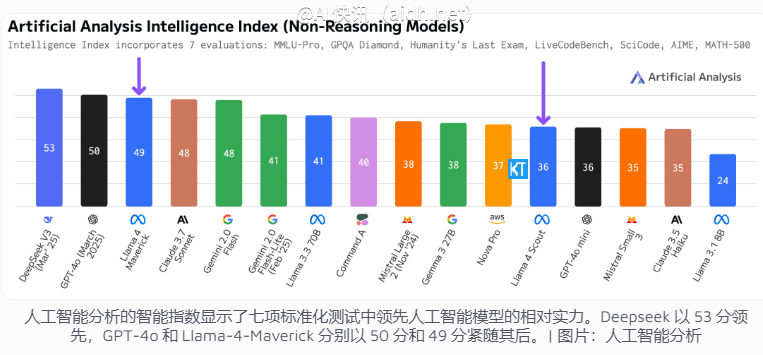
最新的独立评估显示,Meta所推出的Llama4模型中的Maverick和Scout在标准测试中表现出色,但在复杂的长上下文任务中表现欠佳。根据人工智能分析的”智能指数”,Maverick得分为49分,略领先于Claude3.7Sonnet(得分未公开),但稍逊于Deepseek V3(得分为53分);Scout得分为36分,在与GPT-4o-mini相当的同时,优于Claude3.5Sonnet和Mistral Small3.1。两款模型在推理、编码和数学任务中表现稳定,没有明显的弱点。
Maverick的架构效率十分引人注目,其活动参数仅为Deepseek V3的170亿(相较于370亿),总参数占Deepseek V3的60%(4020亿对比6710亿),且能够处理图像而非只限于文本。在价格方面,Maverick的每百万输入/输出代币均价为0.24美元至0.77美元,而Scout为0.15美元至0.4美元,均低于Deepseek V3,甚至比GPT-4o便宜10倍,成为最经济实惠的AI模型之一。
然而,Llama4的发布引发了一些争议。LMArena的基准测试显示,Maverick在Meta推荐的“实验性聊天版本”下排名第二,但在启用“风格控制”后却跌至第五,显示出其依赖格式优化而非纯粹内容质量。一些测试人员对Meta的基准测试可靠性提出了质疑,指出其表现与其他平台有着明显差异。Meta承认优化了人类评估体验,但否认有训练数据作弊的情况发生。
长上下文任务是Llama4的明显弱点。Fiction.live的测试显示,Maverick在128,000个令牌下的准确率仅为28.1%,而Scout则更低,仅有15.6%,远远不如Gemini2.5Pro的90.6%。尽管Meta宣称Maverick支持100万令牌、Scout支持1000万令牌的上下文窗口,但实际表现远未达到标准。研究显示,超大的上下文窗口并没有明显的性能提升,128K以下反而更为实用。
Meta生成AI负责人Ahmad Al-Dahle回应称,早期的不一致性来源于实施问题,而非模型本身的缺陷。他否认了测试作弊的指控,并表示他们正在进行部署优化,预计在数天内会稳定下来。
快讯中提到的AI工具
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/3d81nt1o
暂无评论...

















