智谱清言
中国版对话语言模型,与GLM大模型进行对话
无问芯穹(Infinigence AI),是一个聚焦于AI计算优化能力和算力解决方案的平台,旨在追求大模型落地时的极致能效。通过在“M 种模型”和“N 种芯片”之间构建“M×N”中间层产品,无问芯穹实现了多种大模型算法在多样芯片上的高效、统一部署,从而加速人工通用智能(AGI)在各行业的落地和应用。
无问芯穹为大模型服务平台,这意味着它是一个一站式的AI平台,能够提供完善的GPU选择和配置灵活性,使得AI开发者和企业可以立即着手开发、训练和推理操作。通过预置的主流Pytorch/CUDA镜像,使用者只需简单的配置即可开始全流程的AI开发。这种即插即用的特性不仅减少了技术门槛,也使得公司在实施AI项目时能够节省大量时间与成本。
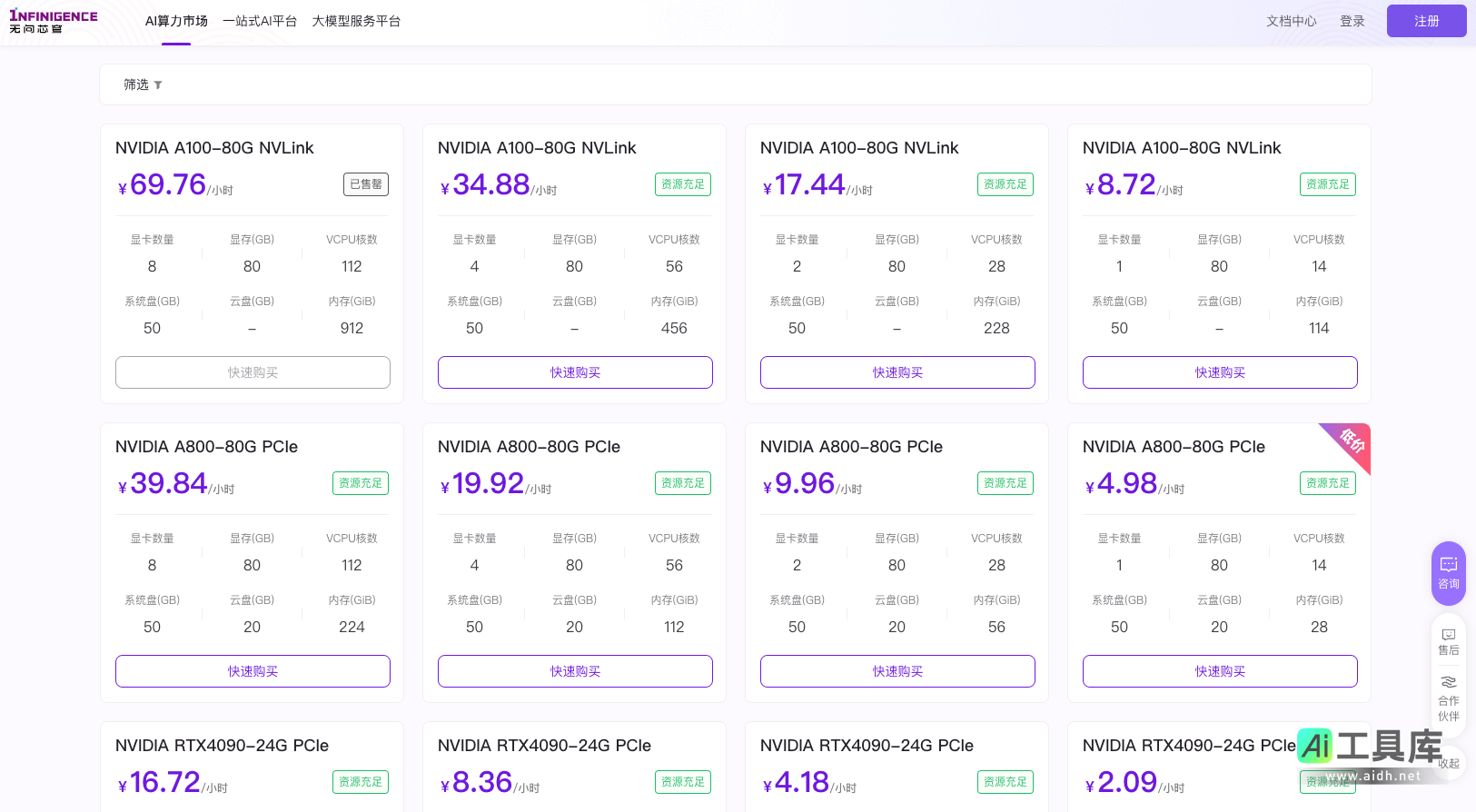
无问芯穹的产品服务不仅满足了高端大模型训练及推理需求,更适用于深度学习、科学计算、图形渲染和视频编辑等多种应用场景。这种多样性和灵活性是无问芯穹的一大优势。而现今AI算力市场活动中,与NVIDIA紧密合作的促销策略提供了更加具有价格竞争力的显卡租赁服务,极大降低了用户的使用门槛,使得更多用户能够在限时优惠期间大展身手。

在无问芯穹的平台中,用户可享受灵活的GPU算力租赁服务,这对于需要高性能计算的企业与开发者而言无疑是巨大的福利。用户可以随时选择购买并根据需求自动调整配置,不论是规模大的企业还是个人开发者,都能按量付费或选择包年包月等多种方式去购买所需的算力权益,最大限度利用算力资源。此种自由的计费方式也为快速变化的市场需求提供了弹性支持。
此外,无问芯穹还提供了专门为企业级用户设计的私有资源池服务。这项服务针对硬件及功能有特殊要求的用户,支持从显存到系统盘的多项配置定制,有助于那些需要按需定制专属计算环境的企业。
该内容由AI导航(aidh.net)汇总整理。
无问芯穹依托其卓越的AI推理引擎,着力改进大语言模型的运行效率。通过提示词缓存技术,其推理速度提升可达50%。这意味着用户可以更快地进行推理操作,加速大规模数据处理和分析的实时性。
在训练大模型时,无问芯穹提供了高效训练方案,使得模型有效训练时长提升30%。这对时间紧迫的项目和需要快速迭代的研发工作流尤为重要。在开发工具方面,无问芯穹提供的AICoder辅助平台,不仅仅预装了Docker镜像,而且支持数据传输和远程连接,让开发者能够更迅速地投入到创造性工作中。
在无问芯穹平台上,用户不仅可以轻松实现在线模型的部署与管理,更可享受集成算力纳管服务。这项服务整合了资源调度、监控与管理以及弹性扩展功能。配合算力运维服务和专业的咨询服务,用户在硬件维护、软件管理、性能监控、安全管理和故障处理等多个方面都能得到专业支持。
针对需要优化算力配置的用户,无问芯穹提供的算力规划、部署和优化建议,使得用户能够更合理地利用平台的优势,显著优化计算任务所需的时间和资源。
选择无问芯穹,是因为它不仅是一个提供AI算力的市场平台,更是一个能够帮助用户最大化价值的智能基础设施提供者。结合多种合作模式,无问芯穹灵活适应不同领域的需求,并以多元化的方式与用户共建AGI时代的智能化基石。通过积累行业专业知识与技术优势,无问芯穹正成为推动AI技术变革的重要力量,引领大模型技术在实际应用中的全面落地。企业和开发者在无问芯穹平台上的逐步深入合作,将在加速AI创新和智能化转型中,创造出无限的潜能和价值。

 豆包
豆包 扣子
扣子 LiblibAI
LiblibAI 提交工具
提交工具