
昆仑万维于今日宣布,正式开源国内首个面向人工智能(AI)短剧创作的视频生成模型 SkyReels-V1,以及国内首个达到 SOTA(State-of-the-Art)水平的、基于视频基座模型的表情动作可控算法 SkyReels-A1。

据昆仑万维官方介绍,SkyReels-V1 针对表演细节进行了精确标注,并对情绪、场景和表演诉求等要素进行细致处理,利用千万级别的高质量好莱坞级别数据进行训练和微调,从而确保模型能够生成高质量的视频内容。

此外,SkyReels-V1 具备“影视级人物微表情表演生成”能力,支持 33 种人物表情与 400 种自然动作的组合,能够细腻地还原真人的情感表达,并支持生成大笑、怒吼、惊讶、哭泣等丰富的微表情。
基于好莱坞级的影视数据训练,SkyReels 生成的每一帧画面在构图、演员站位和相机角度等方面,都具备“电影级的质感”。

SkyReels-V1 不仅支持文本生成视频,还支持图像生成视频,号称是“开源视频生成模型中参数规模最大的支持图像生成视频的模型”,在同等分辨率下,各项指标均达到开源 SOTA 水平。
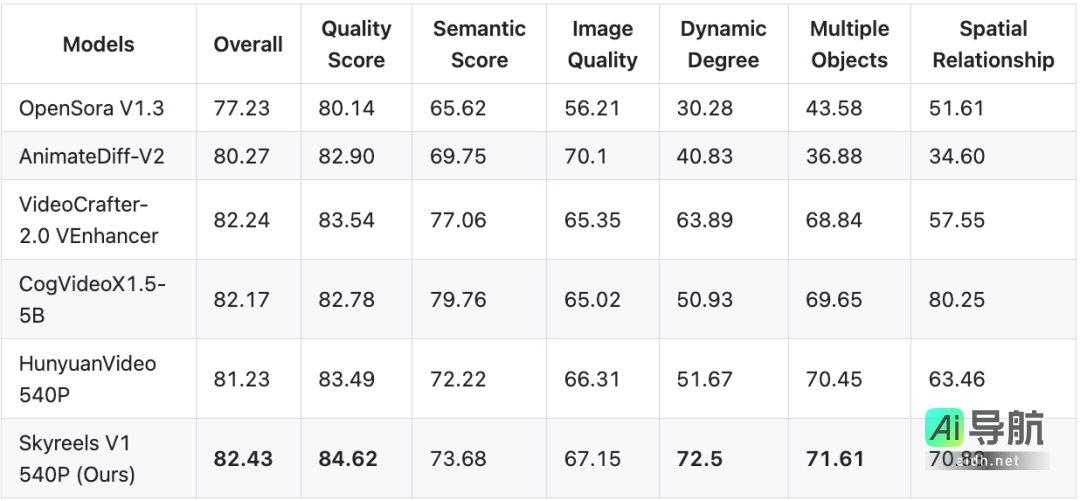
综上所述,SkyReels-V1 具备以下核心功能:
- 影视化表情识别体系:能够精准理解影视戏剧中人物的 11 种表情,如不屑、不耐烦、无助、厌恶等。
- 人物空间位置感知:基于人体三维重建技术,实现对视频中多人空间相对关系的理解,从而助力模型生成影视级的人物站位。
- 行为意图理解:构建超过 400 种行为语义单元,实现对人物行为的精准理解。
- 表演场景理解:实现人物、服装、场景和剧情的关联分析。
在性能方面,得益于自研推理优化框架「SkyReels-Infer」的加持,该模型可实现 544p 分辨率,在单台 4090 显卡上推理用时 80 秒,并支持分布式多卡并行,以及 Context Parallel、CFG Parallel 和 VAE Parallel 等多种并行策略。
此外,该模型采用 fp8 量化以及参数级卸载,满足低显存用户级显卡运行需求;同时支持 Flash Attention 和 SageAttention 等技术,并进行模型编译优化,进一步降低延迟;基于开源 Diffuser 库,提升易用性。
为了实现更加精准可控的人物视频生成,昆仑万维还开源了 SOTA 级别的基于视频基座模型的表情动作可控算法 SkyReels-A1,对标 Runway 的 Act-One。SkyReels-A1 支持视频驱动的电影级表情捕捉。
SkyReels-A1 能够基于任意人体比例(包括肖像、半身及全身构图)生成人物动态视频。
如下图所示,将参考人物图片(上图)和驱动视频(左下)同时作为输入,在 SkyReels-A1 的加持下,可以生成全新的视频,将驱动视频中的面部表情和表演细节“移植”到给定参考图片的人物身上。

AI 工具库开源地址如下:
- SkyReels-V1:https://github.com/SkyworkAI/SkyReels-V1
- SkyReels-A1:https://github.com/SkyworkAI/SkyReels-A1
技术报告:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点


暂无评论...