
DeepSeek 今日正式发布原生稀疏注意力机制(NSA),该机制在硬件层面进行了优化,支持原生可训练的稀疏注意力,旨在实现超快速的长上下文训练与推理。

NSA 的核心构成要素包括:
- 动态分层稀疏策略
- 粗粒度 token 压缩
- 细粒度 token 选择
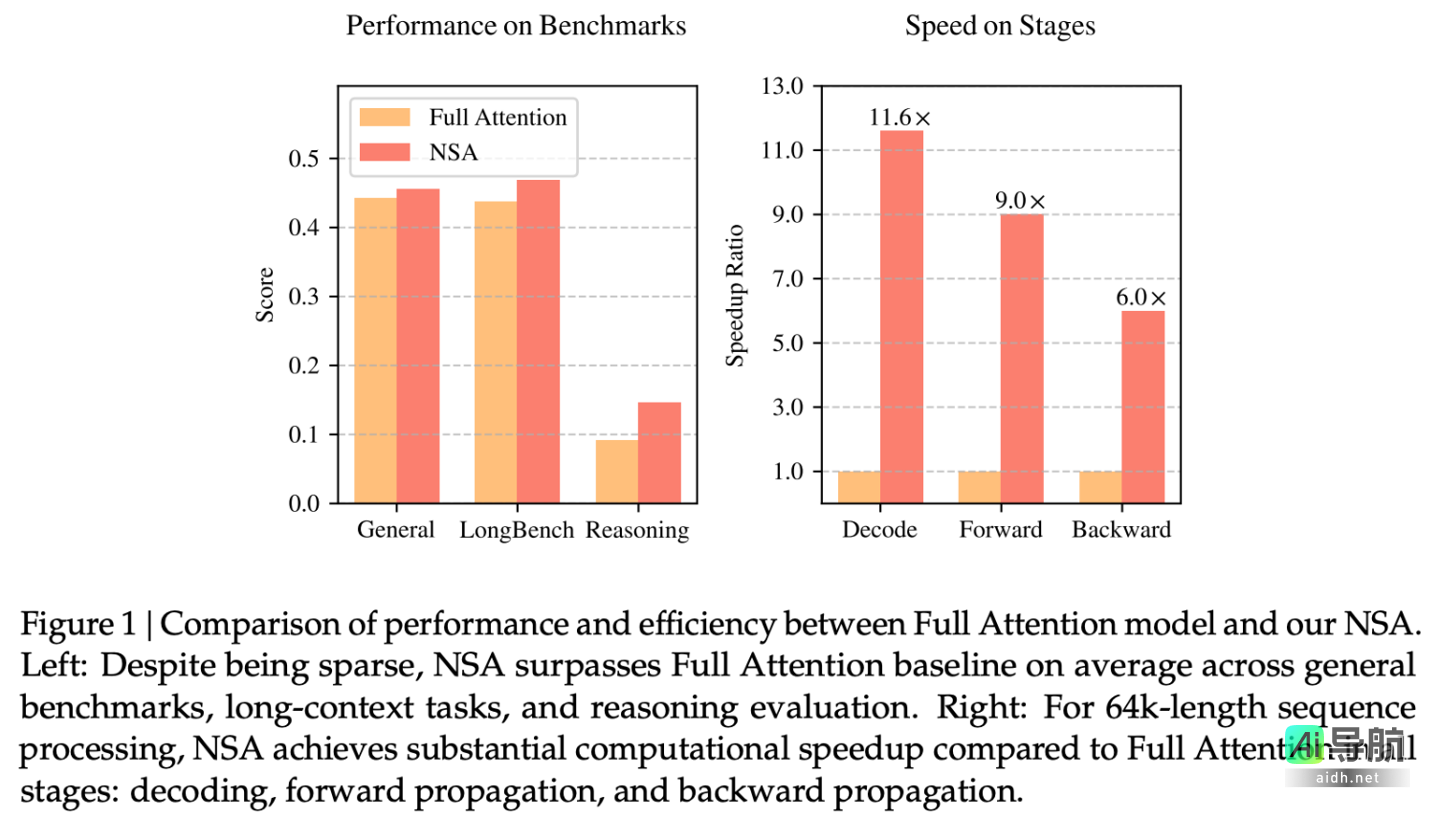
据 DeepSeek 官方介绍,该机制能够优化现代硬件设计,在不影响性能的前提下,加速推理并降低预训练成本。在通用基准测试、长上下文任务以及基于指令的推理等方面,其表现与全注意力模型基本持平甚至更为出色。
AI工具库已收录该论文链接:
文章中提到的AI工具

DeepSeek
深度求索:引领未来人工智能技术的探索与创新
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关AI热点








暂无评论...