

摘要:
在软件开发领域,错误修复一直是一个让人头疼的问题。最近,字节跳动的豆包大模型团队推出了首个多语言软件工程(SW […]

在软件开发领域,错误修复一直是一个让人头疼的问题。最近,字节跳动的豆包大模型团队推出了首个多语言软件工程(SWE)数据集 Multi-SWE-bench,给开发者带来了好消息。这个新数据集的目的是评估和提升大型模型在自动修复代码错误方面的能力。
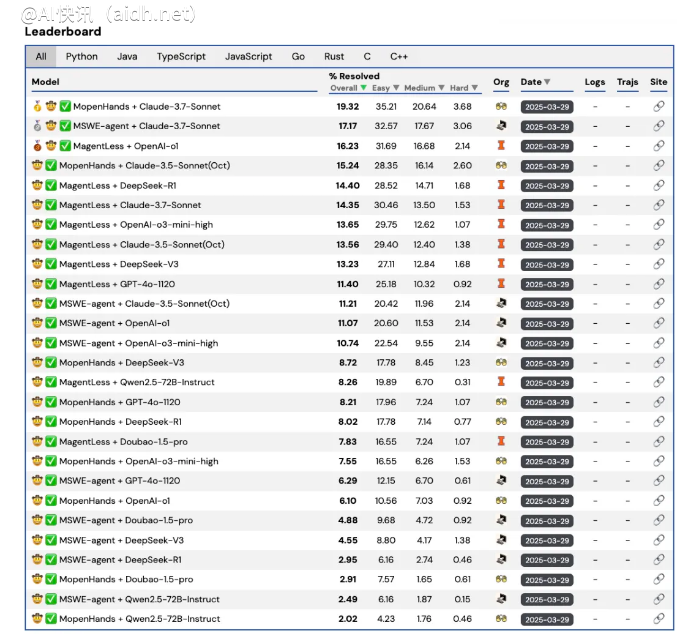
Multi-SWE-bench与过去的单一语言数据集相比,有着显著的扩展。该数据集不仅包含Python,还包括Java、Go、Rust、C、C++、TypeScript和JavaScript等七种主流编程语言,实现了全栈工程的评测基准。这意味着无论开发者使用哪种语言,都能从中获益。
数据集的构建过程同样值得关注。Multi-SWE-bench包含1632个真实的编程实例,所有这些实例都来自GitHub上的问题反馈。为了确保质量,这些实例经过了统一的测试标准和专业开发者的审核筛选,确保每个样本都具有清晰的问题描述、有效的修复补丁和可复现的测试环境。
豆包大模型团队希望通过这个新数据集推动大型模型在多种主流编程语言和真实代码环境中的系统性评测,进一步提升其自动编程能力,朝着更实用和工程化的方向发展。这一努力不仅有助于开发者节省时间,还有助于提升软件开发的效率和质量。
在实际开发中,错误修复不仅仅是技术问题,也影响项目进度和团队士气。因此,Multi-SWE-bench的推出可能成为未来自动化软件工程的关键一环。
字节跳动的这一新数据集标志着代码自动修复技术迈出了重要一步,有望为广大开发者带来便利。
快讯中提到的AI工具
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/uremcff0
暂无评论...