
摘要:
厌倦了只能凝视二维照片中的美好场景?渴望身临其境地体验那些迷人的画面?来自CVPR 2025 的突破性研究—— […]
厌倦了只能凝视二维照片中的美好场景?渴望身临其境地体验那些迷人的画面?来自CVPR 2025 的突破性研究——MIDI(Multi-Instance Diffusion for Single Image to 3D Scene Generation,多实例扩散单图到三维场景生成)——将这一愿望变为现实。这项技术如同一位技艺精湛的魔法师,只需一张普通的二维图片,即可构建出栩栩如生的360度三维场景。

一图胜千言?如今更能“变”出整个世界!
试想,您拍摄了一张阳光洒满的咖啡馆角落照片,照片中包含精致的桌椅、散发着香气的咖啡杯以及窗外婆娑的树影。过去,这只是一张静态的平面图像。但借助 MIDI,您只需将照片输入系统,接下来的过程堪称“点石成金”。
MIDI 的工作原理十分巧妙。首先,它会对输入的单张图像进行**智能分割**,如同一位经验丰富的艺术家,精准识别场景中的各个独立元素,例如桌子、椅子、咖啡杯等。这些被“分解”的图像局部,以及整体的场景环境信息,都成为 MIDI 构建三维场景的重要依据。
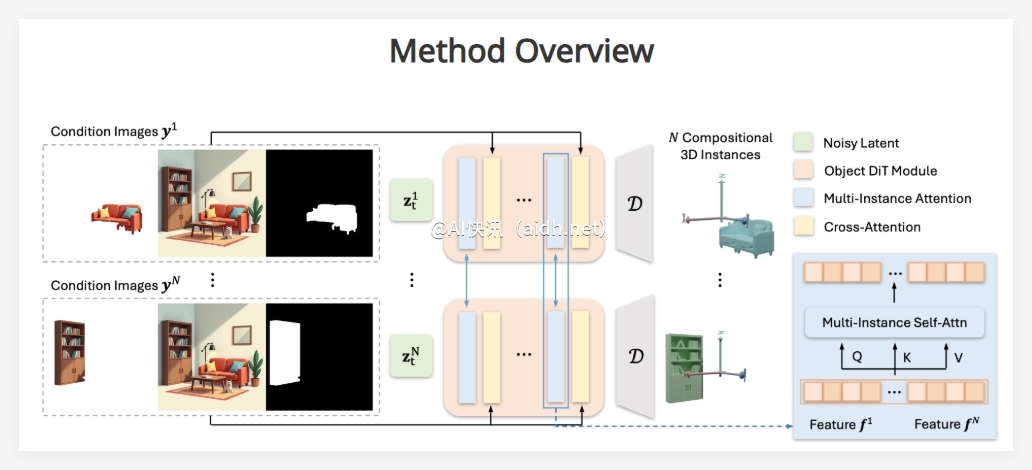
多实例同步扩散,告别“单打独斗”的三维建模
与其他逐个生成三维物体再进行组合的方法不同,**MIDI 采用更高效、更智能的多实例同步扩散方法**。这意味着它能够同时对场景中的多个物体进行三维建模,如同一个乐团同时演奏不同的乐器,最终合奏出和谐的乐章。
更令人惊叹的是,MIDI 引入了一种**创新的多实例注意力机制**。该机制如同场景中不同物体之间的“对话”,有效捕捉物体间的相互作用和空间关系,确保生成的三维场景不仅包含独立的物体,更重要的是,它们之间的摆放位置和相互影响都符合逻辑,浑然一体。这种直接在生成过程中考虑物体间关系的能力,避免了传统方法中复杂的后处理步骤,显著提升了效率和真实感。
细节控和效率党的福音
- 一步到位,快速生成:MIDI 无需复杂的多阶段处理,即可直接从单张图像生成可组合的三维实例。据称,整个处理过程最快仅需 40 秒,对于追求效率的用户而言,无疑是一大福音。
- 全局感知,细节丰富:通过引入多实例注意力层和交叉注意力层,MIDI 能够充分理解全局场景的上下文信息,并将其融入到每个独立三维物体的生成过程中,从而确保场景的整体协调性和细节的丰富度。
- 有限数据,强大泛化:MIDI 在训练过程中巧妙地利用有限的场景级别数据来监督三维实例间的交互,同时融入大量的单物体数据进行正则化,使其在保持良好泛化能力的同时,也能准确生成符合场景逻辑的三维模型。
- 纹理精细,效果逼真:值得一提的是,MIDI 生成三维场景的纹理细节同样出色,这得益于 MV-Adapter 等技术的应用,使最终的三维场景更加真实可信。
可以预见,MIDI 技术的出现将在诸多领域掀起新的浪潮。无论是游戏开发、虚拟现实、室内设计,还是文物数字化保护,MIDI 都将提供一种全新的、高效便捷的三维内容生产方式。想象一下,未来的我们或许只需拍摄一张照片,就能快速构建出一个可交互的三维环境,实现真正的“一键穿越”。
项目入口:https://huanngzh.github.io/MIDI-Page/
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/pto14b99
暂无评论...












