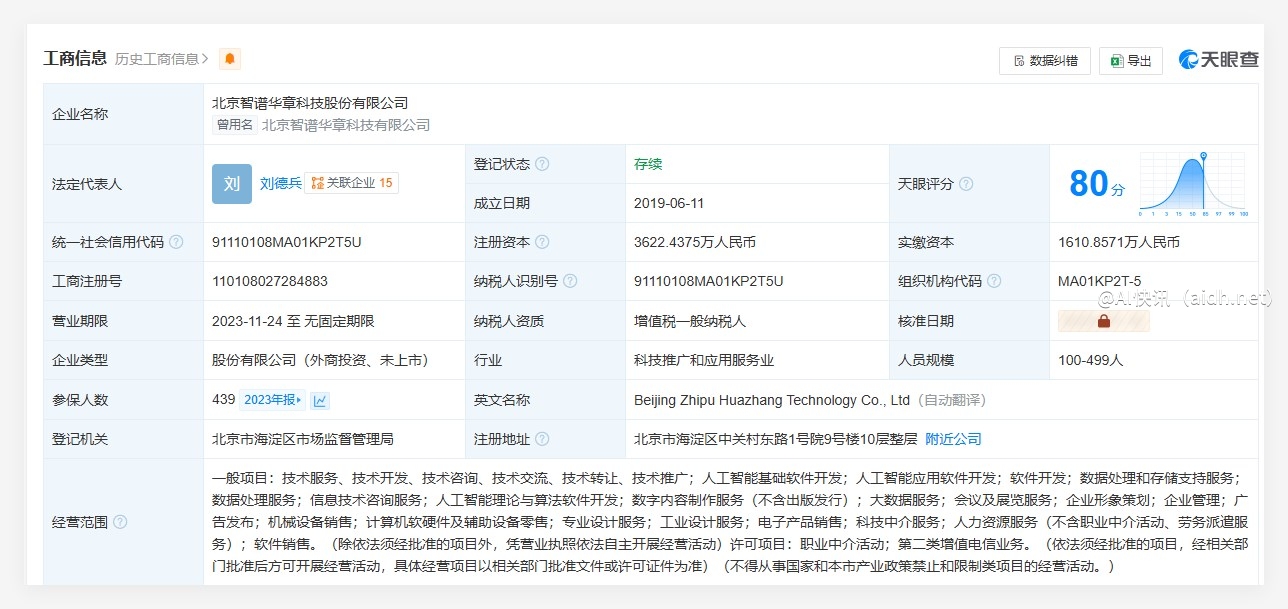
摘要:
智谱大模型于2025年1月16日发布了一系列创新模型,通过bigmodel.cn平台对外开放。此次共发布8款模 […]

智谱大模型于2025年1月16日发布了一系列创新模型,通过bigmodel.cn平台对外开放。此次共发布8款模型,涵盖了“多模态对话”,可应用于语音、图像和视频等多种场景,包括GLM-Voice、GLM-4V、CogView和CogVideoX等不同类型。
特别值得关注的是实时对话模型GLM-Realtime,它能根据用户需求进行快速响应,在保证实时性的前提下,还能提供高质量的Function Call功能。此外,还推出了GLM-4-Air和GLM-4V-Plus模型,进一步提升了推理能力和多模态处理能力。本次发布的多种模型均支持Flash加速能力,能够有效提升推理、图像、视频以及图文创作等任务的效率,实现更快速的应用。
GLM-Realtime在多轮对话中表现出色,它能够在保证对话流畅性的同时,实现高质量的实时响应,使用户获得更自然的交互体验。Realtime API不仅支持流式对话和并发请求,还具备强大的功能,能够满足各类复杂场景下的实时对话需求。Realtime还集成了Function Call功能,可以灵活调用外部API和服务,实现更强大的功能和更智能的交互体验。GLM-Realtime API已在bigmodel.cn平台开放,欢迎体验并提供宝贵建议。
GLM-4-Air在综合能力上实现了显著提升,推出了新版本GLM-4-Air-0111,在知识量、推理能力和多轮对话等方面均有所增强,并支持调用更强大的GLM-4-Plus模型,其效果提升高达50%,模型能力得到了全面升级。多模态对话模型GLM-4V-Plus也进行了更新,能够在图像理解方面实现更精准的识别,支持更大分辨率的图像输入,从而提升多模态交互体验,并有效降低token成本,支持4K高清图像和更长时长的视频处理,在多轮对话中能够实现更准确的理解和更丰富的场景应用。
此次发布的这些创新模型,旨在满足不同用户的需求,并进一步提升大模型在实际应用中的效率。Flash系列模型API的推出,旨在通过底层技术优化,提升各类图像处理、多模态创作、以及音视频生成等任务的效率。目前Flash系列已涵盖了多模态对话模型GLM-4-Flash、图文创作模型GLM-4V-Flash、视频生成模型CogView-3-Flash和多模态视频生成模型CogVideoX-Flash。
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/p169blua
暂无评论...