



摘要:
在不断发展的语言模型领域,研究人员和机构面临多项挑战,包括提升推理能力、提供多语言支持以及有效管理复杂任务。尽 […]
在不断发展的语言模型领域,研究人员和机构面临多项挑战,包括提升推理能力、提供多语言支持以及有效管理复杂任务。尽管小型模型更易获取且成本较低,但通常在性能上不及大型模型。因此,开发中等规模模型以平衡计算效率和强大推理能力已成为当前趋势。
最近,清华大学发布了GLM4系列,尤其是其GLM-Z1-32B-0414变体,成功地克服了这些挑战。GLM4经过在包含15万亿个标记的庞大数据集上的训练,旨在提供可靠的多语言支持,并引入了一种名为“思维模式”的创新推理策略。
该发布使GLM4与其他知名模型如DeepSeek Distill、QwQ和O1-mini齐名,并采用广受欢迎的MIT许可证进行分发。尽管参数规模仅为32亿,但GLM4在推理基准测试中表现出的性能与包含高达6710亿参数的GPT-4o和DeepSeek-V3等更大模型媲美。
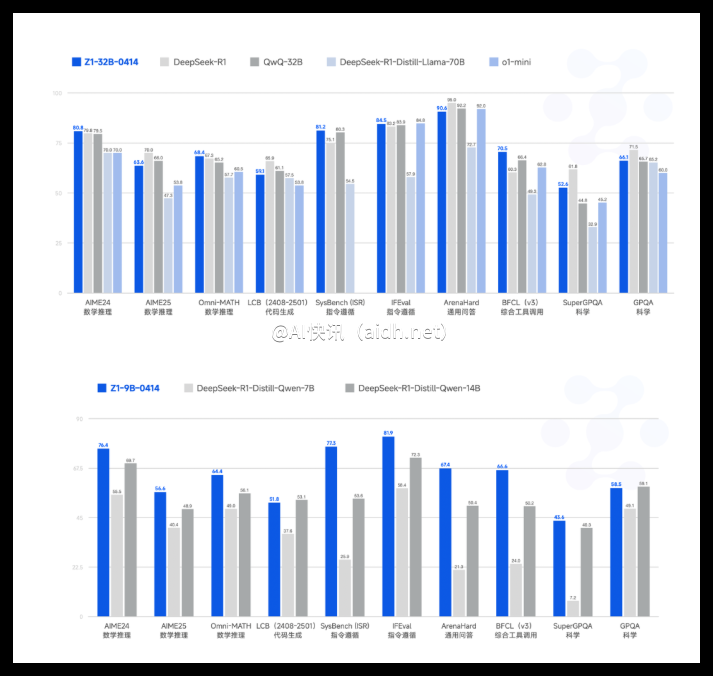
从技术层面来看,GLM-Z1-32B-0414利用高质量的训练数据,包括合成生成的推理任务,以增强其分析能力。该模型融合了先进的拒绝采样和强化学习技术,以提升在基于代理的任务、编码、函数调用和搜索驱动的问答任务中的表现。
此外,其“深度推理模型”变体通过结合冷启动方法与延长的强化学习训练,专门优化于复杂的数学、逻辑和编码任务。在训练过程中采用成对排名反馈机制,提升整体推理效果。
GLM-Z1-Rumination-32B-0414这一高级变体引入了“反思”方法,使得模型能够进行长时间的反思推理,以解决像AI驱动的城市分析等开放复杂问题。该变体结合了先进的搜索工具与多目标强化学习,显著提升了其在研究密集型任务和复杂检索场景中的实用性。而GLM-Z1-9B-0414版本则以其90亿参数展现出了强大的数学和通用推理能力,验证了较小规模模型的实用性。
基准评估数据凸显了GLM4系列的优势。特别是在IFEval指令跟随基准上,GLM4取得了87.6的高分。在零售(68.7)和航空(51.2)等自动化基准任务TAU-Bench上,GLM4也表现出色。在通过SimpleQA评估的搜索增强问答任务中,模型得分高达88.1。
此外,在BFCL-v3基准的函数调用任务中,GLM4整体得分为69.6,几乎与GPT-4o持平。在Moatless框架测试的实际代码修复场景中,GLM4的成功率达到33.8%,显示其实际价值。
GLM4展现了作为有效语言模型系列的潜力,成功弥合了较小可访问模型与传统更大模型之间的性能差距。GLM-Z1系列,特别是32B变体,通过提供强大推理能力,同时保持计算的经济性,展现了平衡和谐的方法。由于采用宽松的MIT许可证,GLM4被定位为研究和企业应用中高性能AI解决方案的重要工具,无需承担传统大型模型所带来的巨大计算开销。
huggingface:https://huggingface.co/THUDM/GLM-Z1-32B-0414
划重点:
- 🌍 GLM4是清华大学发布的32亿参数语言模型,具备强大的多语言和推理能力。
- 📊 该模型在多项基准测试中表现出色,尤其在指令跟随和任务自动化领域,展现了与更大模型相当的性能。
- 🚀 GLM4通过MIT许可证,使得高性能AI解决方案更易获取,适合研究和企业应用。
快讯中提到的AI工具
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/p0t12tgm
暂无评论...

















