

豆包大模型团队今日发布文生图技术报告,详细阐述Seedream 2.0图像生成模型的技术细节,涵盖数据构建、预训练框架和强化学习与人类反馈 (RLHF) 全流程。Seedream 2.0自2024年12月在豆包APP和即梦上线以来,已服务数亿用户,并受到专业设计师的广泛好评。 与Ideogram 2.0、Midjourney V6.1等主流模型相比,Seedream 2.0在中英文双语理解、图像美感和指令遵循等方面均有显著提升,尤其解决了现有模型中常见的文本渲染不佳及对中国文化理解不足等问题。


Bench-240评测基准测试结果显示,Seedream 2.0在英文提示词生成内容的结构合理性和文本理解准确性方面表现优异;中文生成与渲染文字可用率达78%,完美响应率为63%,均显著高于业界其他模型。

在技术实现方面,团队进行了多项创新。数据预处理环节采用基于“知识融合”的四维数据架构,平衡数据质量与知识多样性,并通过智能标注引擎的三级认知进化提升模型的理解和识别能力,同时对数据处理流程进行工程化重构以提高效率。
预训练阶段,团队重点关注双语理解和文字渲染。团队采用原生双语对齐方案,结合微调大型语言模型 (LLM) 和专用数据集的构建,突破了语言和视觉维度的壁垒;双模态编码融合系统能够同时处理文本语义和字体字形信息;改进的DiT架构(包含QK-Norm和Scaling ROPE技术)提升了训练稳定性并实现了多分辨率图像生成。
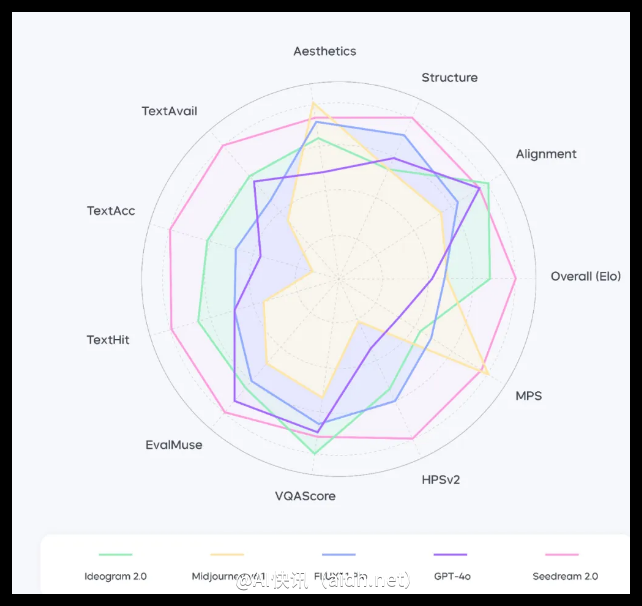
注:以上数据基于英文提示词,以最佳指标为参照系进行归一化处理。
在RLHF阶段,团队开发的优化系统从多维度偏好数据体系、三个不同奖励模型以及反复学习驱动模型进化三个方面入手,有效提升了模型性能,各奖励模型的得分在迭代过程中稳步上升。
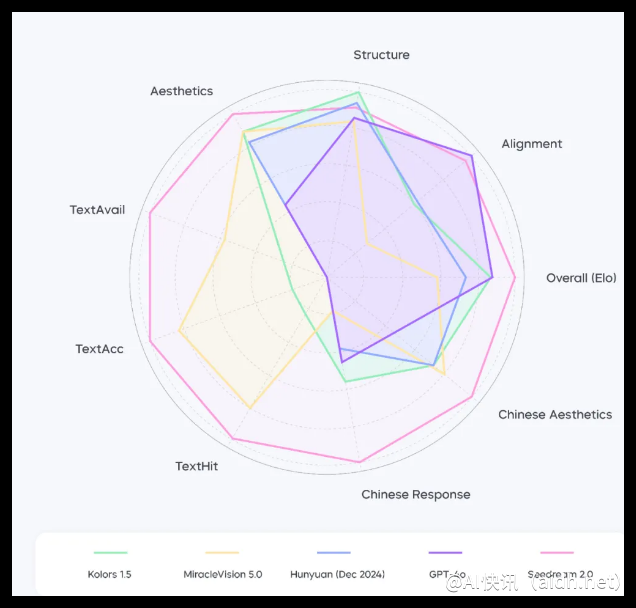
注:以上数据基于中文提示词,以最佳指标为参照系进行归一化处理。
本次技术报告的发布,体现了豆包大模型团队对推动图像生成技术发展的坚定决心。未来,团队将持续探索创新技术,提升模型性能,深入研究强化学习优化机制,并积极分享技术经验,推动行业发展。
快讯中提到的AI工具
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/ln61eavu
暂无评论...






