
摘要:
近日,人工智能芯片领域的领军企业英伟达的研究人员发布了一项名为“FFN融合”(FFN Fusion)的创新架构 […]
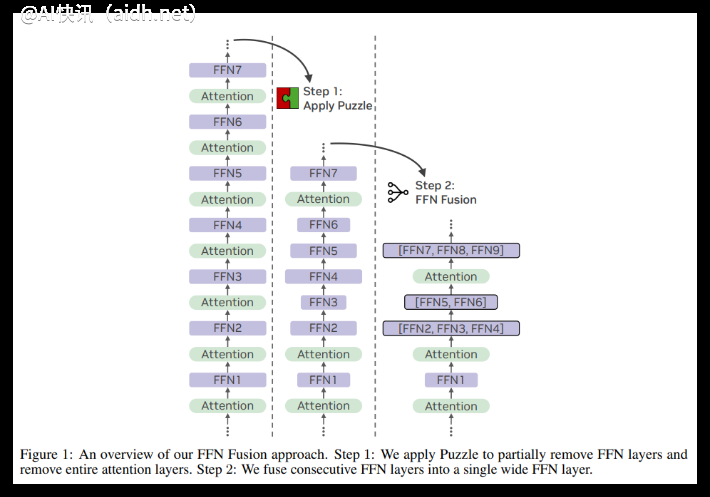
近日,人工智能芯片领域的领军企业英伟达的研究人员发布了一项名为“FFN融合”(FFN Fusion)的创新架构优化技术。该技术旨在解决Transformer架构中存在的串行计算瓶颈问题,显著提升大型语言模型(LLMs)的推理效率,从而为更广泛的高性能AI应用部署铺平道路。
近年来,大型语言模型在自然语言处理、科学研究和对话代理等领域展现出强大的能力。然而,随着模型规模和复杂性的不断增加,推理过程所需的计算资源也大幅增长,导致效率方面存在瓶颈。Transformer架构作为LLM的基础,其交替的注意力机制和前馈网络(FFNs)层需要按顺序处理输入。当模型规模扩大时,这种串行结构会显著增加计算和GPU之间的通信成本,降低效率并提高部署成本。尤其是在需要快速生成多个token的场景(如实时AI助手)中,这个问题更加突出。
为了解决这一挑战,英伟达的研究人员提出了FFN融合技术。该技术的核心思想是将模型中连续的、相互依赖性较低的FFN层合并为一个更宽的FFN。研究人员观察到,在LLM中经常存在较长的连续FFN序列,在移除注意力层后,这些序列之间的依赖性很小,因此可以并行执行。
FFN融合的数学基础在于将多个串联FFN的权重进行拼接,从而创建一个等效的、可以并行计算的单一模块。实验证明,融合后的FFN保持了与原始FFN相同的表示能力。
英伟达的研究人员将FFN融合技术应用于Meta的Llama-3.1-405B-Instruct模型,创建了一个名为Ultra-253B-Base的新模型。实验结果显示,Ultra-253B-Base在推理速度和资源效率方面取得了显著提升:在批量大小为32时,推理延迟降低了1.71倍,每个token的计算成本下降了35倍。
此外,Ultra-253B-Base在多个权威评测基准上表现出色,并且仅包含2530亿参数,相较于原始的4050亿参数模型,表现相当甚至更优。内存使用量也减少了一半,多亏了kv-cache的优化。
研究人员通过余弦距离分析FFN层之间的输出,确定了最佳选择的低相互依赖性区域进行融合。FFN融合技术已在不同规模的模型(包括490亿、700亿和2530亿参数)上验证,表现出良好的通用性。
这项研究表明,通过深入分析和巧妙的架构设计,可以显著提升LLM的效率。FFN融合为设计更并行化、更适应硬件的LLM奠定了基础。虽然全面并行化Transformer模块面临更多挑战,但FFN融合的成功为未来LLM的效率优化指明了一个重要的方向。
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/lb9qk8pk
暂无评论...


















