
摘要:
北京大学张牧涵团队提出了一种全新的框架——长输入微调(Long Input Fine-Tuning, LIFT […]
北京大学张牧涵团队提出了一种全新的框架——长输入微调(Long Input Fine-Tuning, LIFT)。该框架的核心在于将长输入文本的训练融入模型参数中,使即便是具有短上下文窗口的模型亦能具备处理长文本的能力。这一方法颠覆了传统的长文本处理理念,重点不再是扩大上下文窗口的无尽探索,而是将长文本的知识内化为模型的参数,类似于人类将工作记忆转变为长期记忆的过程。
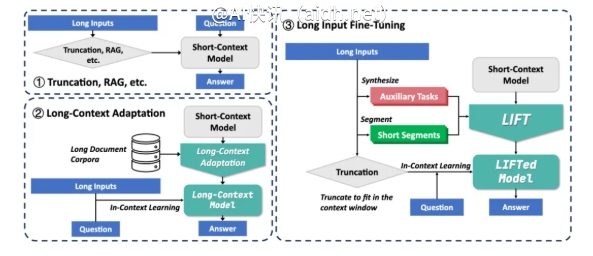
当下,大型模型在处理长文本时面临两大主要挑战:
一方面,传统注意力机制的复杂度呈平方级别增长,导致在处理长文本时需要付出巨大的计算和内存成本;另一方面,模型在理解散布于长文本各处的长程依赖关系时面临困难。
现有的解决方案,如检索增强生成(RAG)和长上下文适配各自存在局限性:
RAG依赖于准确的检索,容易引入噪声,从而导致幻觉现象;而长上下文适配的推理复杂度较高,且上下文窗口依然受限。
在此背景下,LIFT的技术创新主要体现在以下三个关键组件上:
动态高效的长输入训练
通过分段语言建模的方式,LIFT将长文本切分为重叠的片段,从而有效避免因上下文过长所带来的推理复杂性提高和长程依赖的丢失。训练复杂度与长文本长度呈线性关系增长。
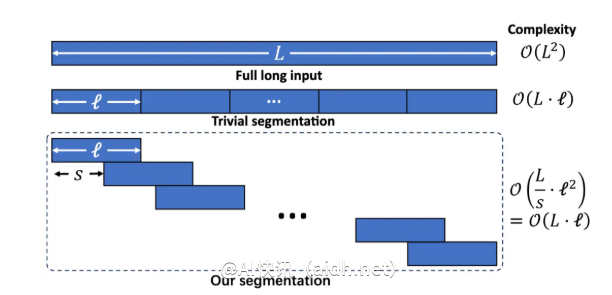
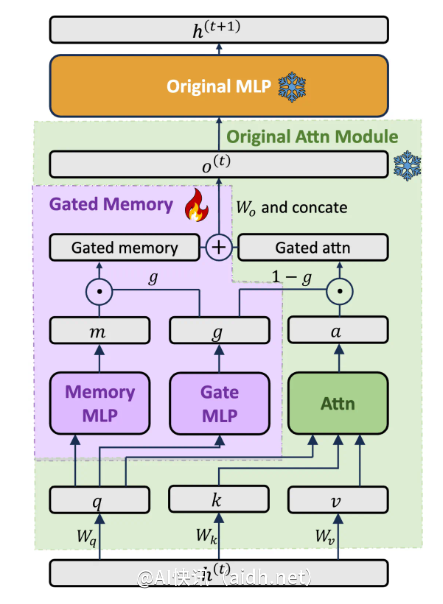
平衡模型能力的门控记忆适配器
LIFT设计了专门的门控记忆适配器(Gated Memory Adapter)架构,能够动态平衡原始模型的上下文学习能力与对长输入的记忆理解。此架构允许模型根据查询自动调节应用多少来自LIFT的记忆内容。
辅助任务训练
LIFT通过预训练的大型语言模型(LLM)自动生成基于长文本的问答类辅助任务,以补偿模型在切段训练中可能损失的能力,从而帮助模型学会如何利用长文本中的信息来回答问题。
实验结果显示,LIFT在多个长上下文基准测试中取得了显著的提升:
在LooGLE长依赖问答任务中,Llama38B模型的正确率从15.44%提高至29.97%;在LooGLE短依赖问答任务中,Gemma29B模型的正确率从37.37%提高至50.33%;此外,LongBench的多个子任务中,通过LIFT处理的Llama3在五个子任务中的四个任务表现明显提升。
消融实验结果表明,使用门控记忆架构的模型,相较于采用PiSSA微调的原始模型,在LooGLE短答案问答(ShortQA)数据集上的GPT-4分数提升了5.48%。
然而,尽管LIFT取得了显著成就,仍存在一些局限:
对于需要精确信息提取的“海底捞针”任务,LIFT的效果并不理想。同时,模型提取由LIFT获得的参数化知识的能力仍待优化;辅助任务的设计过于依赖下游测试任务,从而限制了其通用性;在如何更好地平衡记忆与原有能力之间的关系上,仍需进一步的研究探索。
研究团队呼吁社区共同探索LIFT在更广泛的训练数据、丰富的模型架构、先进的辅助任务设计以及强大的计算资源支持下的潜在可能性。
总结来看,LIFT为长文本处理开辟了一种全新的范式,将上下文知识转化为参数化知识。这一思路与人类记忆中短期记忆转化为长期记忆的过程相似。尽管全面解决长上下文的挑战尚需时日,LIFT无疑为该领域的发展开辟了富有潜力的研究方向。
论文地址:https://arxiv.org/abs/2502.14644
快讯中提到的AI工具

GPT-4
OpenAI 发布的最新一代语言模型
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/hrg7nnta
暂无评论...


















