
摘要:
近日,阿里云的人工智能大模型系列Qwen迎来了重要进展,其下一代模型Qwen3的支持已正式合并至vLLM(高效 […]
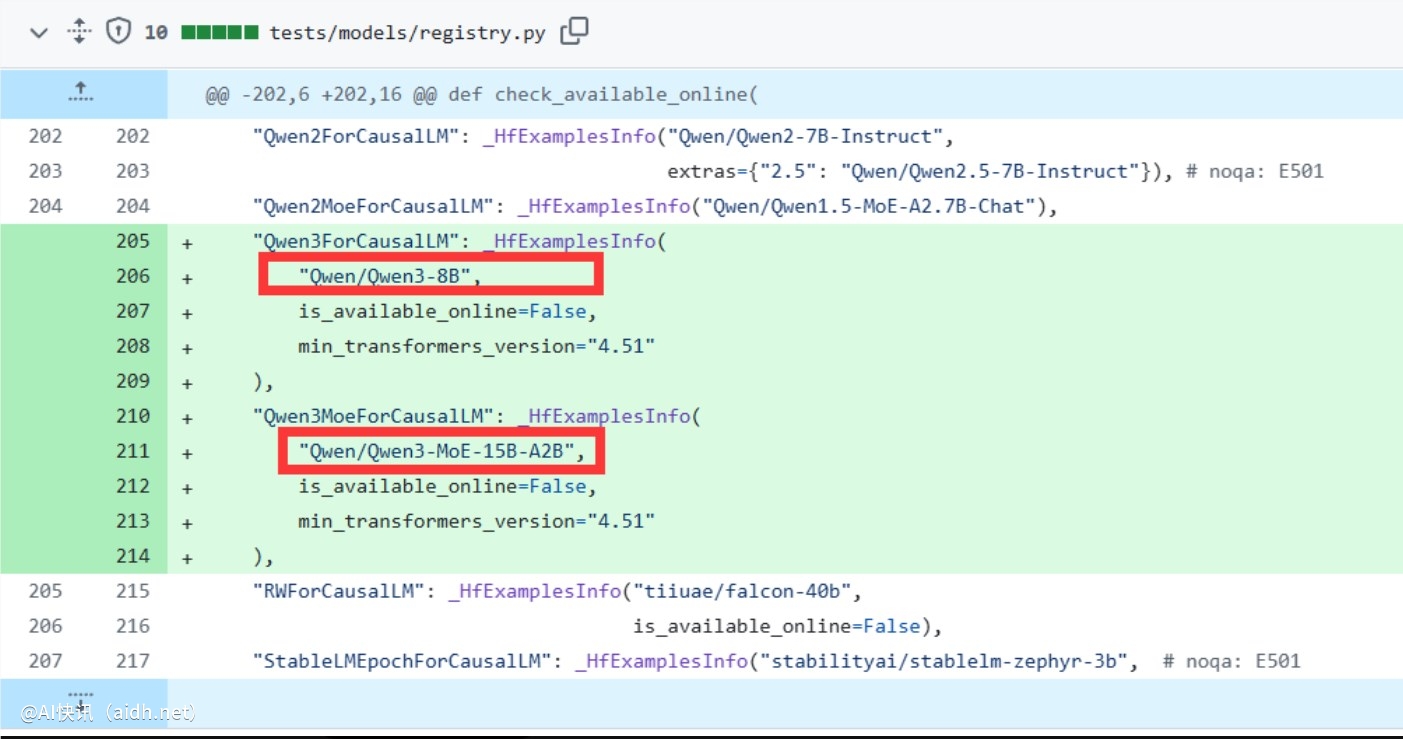
近日,阿里云的人工智能大模型系列Qwen迎来了重要进展,其下一代模型Qwen3的支持已正式合并至vLLM(高效大语言模型推理框架)的代码库中。这一消息引起了科技领域的广泛讨论,标志着Qwen3的发布即将到来。据悉,Qwen3将包含至少两个版本:Qwen3-8B和Qwen3-MoE-15B-A2B,分别代表不同规模和架构的创新尝试,为开发者和企业用户带来更多期待。
Qwen3-8B作为系列的基础模型,预计将延续Qwen家族在语言理解与生成任务上的优异表现。业界推测,这一版本可能在多模态能力上取得突破,能够同时处理文本、图像甚至其他数据类型,满足更广泛的应用场景需求。另一方面,Qwen3-MoE-15B-A2B采用了混合专家(Mixture-of-Experts,MoE)架构,拥有15亿参数,其中约2亿为活跃参数。这种设计旨在通过高效的专家路由机制,在保持较低计算成本的同时实现接近更大模型性能水平。分析人士认为,如果Qwen3-MoE-15B-A2B能在性能上与之前的Qwen2.5-Max媲美(一个以高智能著称的模型),其在实际应用中的潜力将不容忽视。
此次vLLM对Qwen3的支持合并,意味着开发者可以利用高性能推理框架轻松部署Qwen3模型,实现快速、稳定的推理任务。vLLM以其高效的内存管理和并行处理能力而闻名,能够显著提升大型模型在生产环境中的运行效率。这一进展不仅为Qwen3的实际应用打下了基础,也进一步巩固了阿里云在开源AI生态中的影响力。
尽管Qwen3的具体功能和性能细节尚未完全公开,业界对其寄予厚望。Qwen2.5系列在编码、数学推理和多语言任务中展现出超越同行的实力,Qwen3被期待在这些领域取得更大突破,尤其是在资源受限环境下的表现。引入MoE架构也引发了讨论:相比传统密集模型,Qwen3-MoE-15B-A2B在能效比上可能具有优势,适合部署在边缘设备或中小型服务器上。然而,也有声音认为,15亿参数规模相对较小,是否能完全满足复杂任务的需求尚需进一步验证。
阿里云近年来在人工智能领域持续投入,成为全球开源模型开发的重要力量。每一代Qwen模型从Qwen1.5到Qwen2.5的迭代都伴随着技术与生态的双重进步。Qwen3的到来不仅是阿里云技术升级的体现,也是在全球人工智能竞争中赢得先机的重要一步。可以预见,随着更多细节的披露和模型的正式发布,Qwen3将在开发社区和企业应用中掀起新的热潮,为从智能助手到自动化流程的多种场景带来新的活力。
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/dd992hik
暂无评论...


















