摘要:
据相关资料显示,CLIP(Contrastive Language-Image Pre-training)是一 […]

据相关资料显示,CLIP(Contrastive Language-Image Pre-training)是一种新兴的视觉模型训练方法。它通过在大规模图像-文本数据上进行对比学习,使模型能够理解图像和文本之间的关系。
CLIP 能够实现零样本学习、少样本学习以及传统监督学习等多种学习范式。这意味着它既能处理未见过的数据,又能通过少量示例快速适应新任务。例如,通过对图像进行分类或根据文本描述检索相关图像,CLIP 展示了其强大的通用性和适应性。
总而言之,CLIP 的核心优势在于其能够利用大规模数据进行预训练,从而获得强大的图像和文本理解能力,并能够灵活应用于各种下游任务,而无需进行大量的特定任务训练。
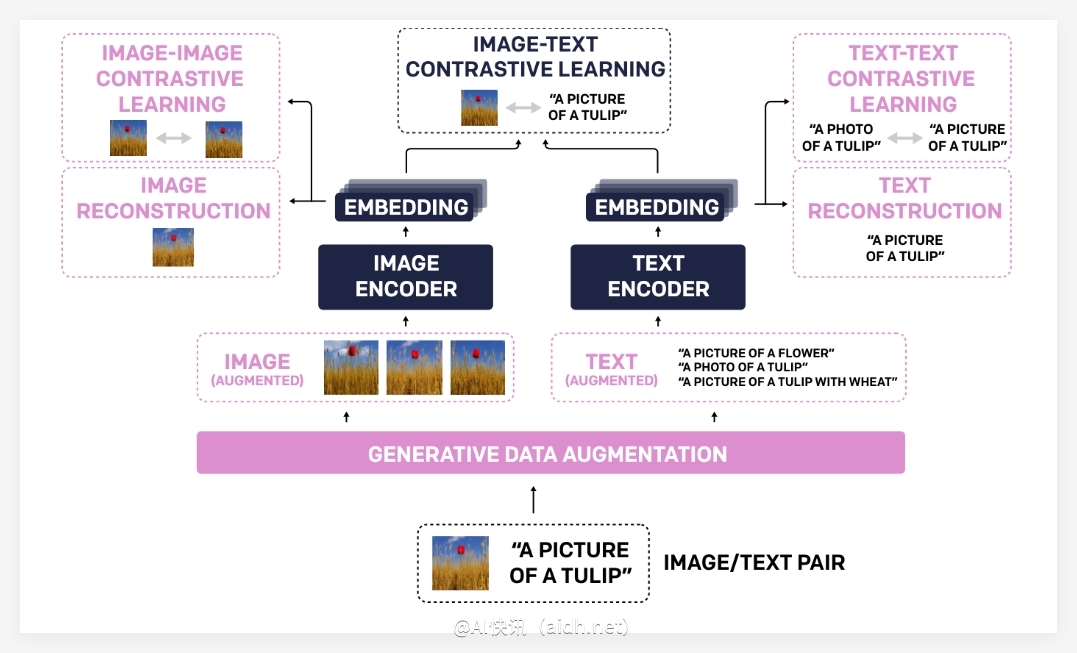
最近,CLIP 在跨模态检索任务中展现了巨大的潜力。为了进一步提升 CLIP 的性能,研究人员提出了 LLM2CLIP 框架,该框架利用大型语言模型(LLMs)生成更具信息量的文本描述。通过这种方式,LLMs 能够有效地补充 CLIP 的视觉表征能力。
具体来说,LLM2CLIP 框架采用了一种名为“提示优化”的技术,该技术旨在利用 LLM 为图像生成更丰富的文本描述,从而增强模型的理解能力。
为了验证 LLM2CLIP 的有效性,研究人员使用了多个公开数据集进行实验,包括 CC-3M、CC-12M、YFCC-15M 和 Recaption-1B。实验结果表明,LLM2CLIP 方法能够显著提升 CLIP 和 EVA 模型在图像-文本检索任务中的性能。
值得一提的是,在 LLaVA-1.5 基准测试中,通过结合 LLM2CLIP 方法,模型在视觉问答任务中的性能提高了 16.5%,超越了当前最先进的 EVA02 模型。这一结果充分证明了 LLM2CLIP 在提升跨模态理解能力方面的巨大潜力,尤其是在数据标注成本较高的情况下。
模型链接:https://huggingface.co/collections/microsoft/llm2clip-672323a266173cfa40b32d4c
代码链接:https://github.com/microsoft/LLM2CLIP/
论文链接:https://arxiv.org/abs/2411.04997
核心要点:
✨ LLM2CLIP 通过利用大型语言模型增强 CLIP 的文本表征能力,从而提升了跨模态检索和视觉问答任务的性能。
🔍 该框架采用“提示优化”技术,利用 LLM 为图像生成更丰富的描述性文本,从而提升模型的理解能力。
🌎 LLM2CLIP 在多个公开数据集上取得了显著的性能提升,证明了其在提升跨模态理解能力方面的有效性,尤其是在标注数据有限的情况下。
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/9csgmb8o
暂无评论...