最近,中国科学院自动化研究所和中科紫东太初团队合作推出了一项名为Vision-R1的全新方法。该方法采用了类似 […]
最近,中国科学院自动化研究所和中科紫东太初团队合作推出了一项名为Vision-R1的全新方法。该方法采用了类似R1强化学习技术,显著增强了视觉定位的能力。相较于目前参数规模超过10倍的最优模型(SOTA),Vision-R1在目标检测和视觉定位等复杂任务中实现了50%的性能提升。
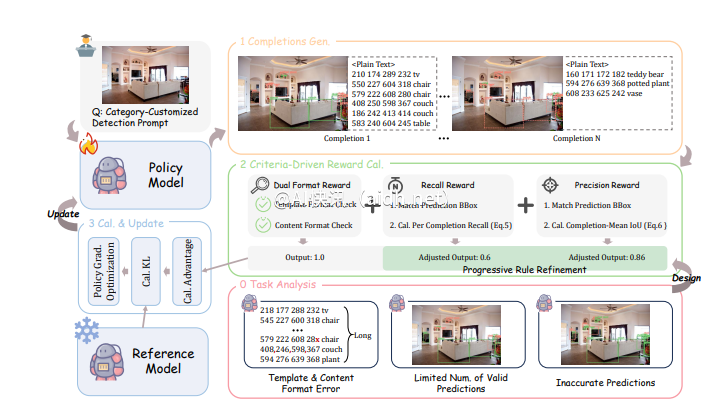
通常,图文大模型采用“预训练 + 监督微调”的方式提高对用户指令的响应能力,但这种方法存在着资源消耗和训练效率上的挑战。Vision-R1通过结合高质量的指令对齐数据和强化学习,开创性地解决了这一难题。该方法通过设计一种视觉任务评估驱动的奖励机制,为模型的目标定位能力提供了有力支持。
具体而言,Vision-R1的奖励机制包括四个核心部分:采用多目标预测方式确保在密集场景中有效评估预测质量;设计双重格式奖励解决长序列预测中格式错误问题;召回奖励鼓励模型尽可能识别更多目标;精度奖励确保生成的目标框质量更高。这些设计相互配合,形成了“1+1>2”的优化效果,使得模型在复杂视觉任务中表现更出色。
为了解决预测高质量目标框的挑战,研究团队提出了一种渐进式规则调整策略,通过动态调整奖励计算规则,促使模型持续提升性能。训练过程分为初学阶段和进阶阶段,逐步提高奖励标准,实现基础到高精度的转变。
在一系列测试中,Vision-R1在经典目标检测数据集COCO和多样场景的ODINW-13上表现卓越。经过Vision-R1训练后,无论是在基础性能方面,模型的表现都有显著提升,更接近专业定位模型。这种方法不仅有效提升了图文大模型的视觉定位能力,还为未来的多模态AI应用提供了新的研究方向。
想了解更多信息,请查看项目地址:https://github.com/jefferyZhan/Griffon/tree/master/Vision-R1。












