
摘要:
最近,全球芯片与人工智能技术领军企业英伟达(NVIDIA)推出了一款备受瞩目的新开源大语言模型——Llama3 […]
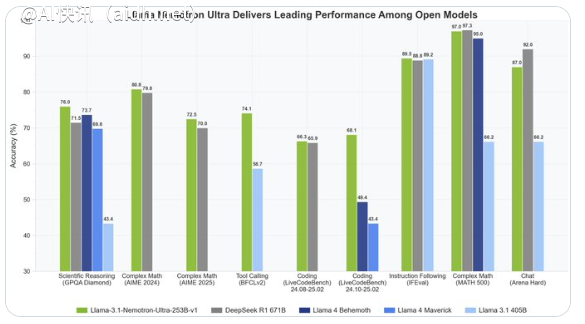
最近,全球芯片与人工智能技术领军企业英伟达(NVIDIA)推出了一款备受瞩目的新开源大语言模型——Llama3.1Nemotron Ultra253B,引起了人工智能领域的广泛关注。该模型是在Meta的Llama-3.1-405B基础上开发而来,在性能方面超越了Llama4Behemoth和Maverick等竞争对手,通过创新技术的优化,不仅在资源利用率和多任务能力上表现出色,还为人工智能应用的广泛应用提供了新的可能性。
Llama3.1Nemotron Ultra253B拥有2530亿个参数,支持长达128K tokens的超长上下文处理,使其能够轻松处理复杂文本输入并保持逻辑连贯性。相较于前代模型,在推理、数学运算、代码生成、指令遵循、RAG和工具调用等关键领域展现出显著提升。Nemotron Ultra在解决复杂数学问题、生成高质量代码以及执行多步指令等任务时表现出色,以惊人的精准度和稳定性为开发者和企业用户提供了强大的智能支持。
这一突破性性能得益于英伟达在模型优化上的多项技术创新。神经架构搜索(Neural Architecture Search,NAS)技术通过系统化探索网络结构,显著降低了模型的内存消耗,确保在资源受限环境下高效运行。此外,英伟达首创的垂直压缩技术进一步优化了计算效率,提升了推理任务的吞吐量,降低了延迟。据悉,该模型能够在单个8x H100GPU节点上完成推理,这使得在数据中心或边缘计算场景下具有极高的部署灵活性。
相较于市场上其他大型语言模型,Nemotron Ultra在性能与效率的平衡上表现突出。尽管参数规模小于某些超大型模型,但通过智能架构设计,在多项基准测试中已超越了竞争对手,包括Llama4Behemoth。特别是在需要深度推理和创造性输出的任务中,该模型展现出接近甚至超越顶级商业模型的潜力。作为开源模型,Nemotron Ultra的完整权重已通过Hugging Face平台开放,开发者可以免费获取和定制,进一步推动了人工智能技术的民主化进程。
然而,这一技术突破也带来了一些待解之谜。尽管Nemotron Ultra在性能上令人振奋,其在超大规模任务或特定领域的极限表现仍需更多实际验证。此外,开源模型的广泛应用可能带来数据安全和伦理使用方面的挑战,英伟达未来可能需要在技术支持和规范制定上投入更多精力。
作为人工智能领域的又一里程碑,Llama3.1Nemotron Ultra253B体现了英伟达在硬件与算法协同优化方面的领先地位,为行业树立了性能与效率兼顾的新标杆。无论是智能助手、自动编程还是企业级知识管理,该模型的多功能性正在重新定义人工智能应用的边界。可以预见,随着开发者社区的深入探索,Nemotron Ultra将在全球范围内引发新一轮技术热潮,为人工智能的未来发展注入无限可能。
快讯中提到的AI工具

Hugging Face
机器学习和人工智能技术的平台
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/6d33fkb0
暂无评论...


















