摘要:
最近,DeepSeek 和清华大学的研究人员联合发布了一篇新论文,讨论了奖励模型推理时的 Scaling 方法 […]
最近,DeepSeek 和清华大学的研究人员联合发布了一篇新论文,讨论了奖励模型推理时的 Scaling 方法,使得 DeepSeek R2 在性能上似乎更进一步。目前,强化学习在大型语言模型的大规模后训练阶段广泛应用,但面临一个挑战,即如何为大型语言模型提供准确的奖励信号。
研究人员发现,采用点式生成式奖励建模(GRM)可以提升模型的适应能力和推理阶段的可扩展性。为此,他们提出了自我原则点评调优(SPCT)学习方法,通过这种训练得到了 DeepSeek – GRM 模型,例如基于 Gemma -2-27B 训练的 DeepSeek – GRM -27B。实验结果显示,SPCT 明显提升了 GRM 的质量和可扩展性,在多项基准测试中表现优于现有的方法和模型。此外,研究人员还引入了元奖励模型(meta RM)来引导投票过程,从而提升了推理性能。
SPCT 方法包括两个阶段。第一阶段是拒绝式微调作为冷启动阶段,让 GRM 能够适应不同的输入类型并按正确格式生成自我原则和点评内容。研究人员采用点式 GRM,同时引入提示式采样以提高预测奖励与真实奖励的一致性。第二阶段是基于规则的在线强化学习,采用规则化的结果奖励,鼓励 GRM 生成更好的自我原则和点评内容,提高推理阶段的可扩展性。
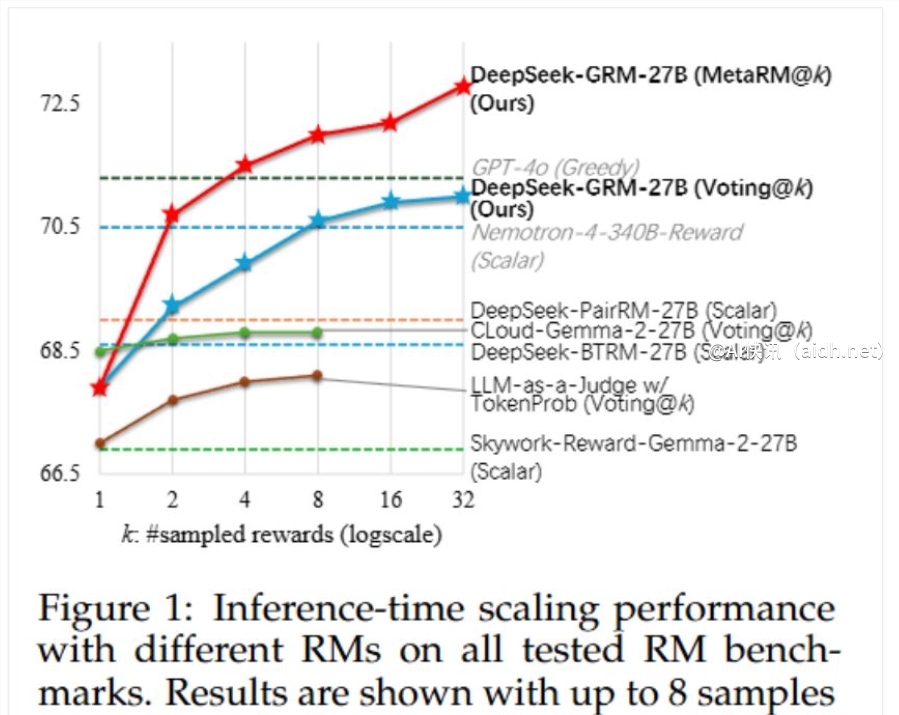
为了提升 DeepSeek – GRM 的性能,研究团队还探索了推理时的扩展策略。通过生成奖励进行投票,扩大奖励空间,提高最终奖励的质量。同时,他们使用训练好的元奖励模型来引导投票,过滤掉低质量的样本。实验结果显示,DeepSeek – GRM -27B 在整体性能上表现出色,同时推理时的扩展也进一步提升了性能。消融分析显示,在线训练对于 GRM 非常重要,原则生成也对模型性能至关重要。此外,研究还证实了 DeepSeek – GRM -27B 在推理时扩展方面的有效性,优于简单地增加模型规模。
要点总结:
- DeepSeek 和清华研究人员提出了自我原则点评调优(SPCT)方法以及引入元奖励模型(meta RM),提升了奖励模型推理时的可扩展性,构建了 DeepSeek – GRM 系列模型。
- SPCT 方法分为拒绝式微调和基于规则的在线强化学习两个阶段,提高了 GRM 的质量和可扩展性,使得 DeepSeek – GRM -27B 在基准测试中表现出色。
- 研究团队探索了推理时的扩展策略,通过生成奖励投票和元奖励模型引导投票提升性能,证明 DeepSeek – GRM -27B 推理时的扩展性有效性优于简单扩大模型规模。
快讯中提到的AI工具

DeepSeek
深度求索:引领未来人工智能技术的探索与创新
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/56lched3
暂无评论...











