
摘要:
腾讯开源团队于3月27日宣布推出了一项创新的多模态理解技术——HaploVL。该技术旨在通过单个Transfo […]
腾讯开源团队于3月27日宣布推出了一项创新的多模态理解技术——HaploVL。该技术旨在通过单个Transformer架构实现高效的多模态融合,显著提升人工智能在视觉和语言交互中的性能,尤其在细粒度视觉理解任务上。
近年来,多模态大模型(LMMs)在人工智能领域迅速兴起,能够实现复杂的视觉-语言对话和交互。然而,现有的多模态模型大多采用“视觉编码器 + 大语言模型”的组合架构,虽然有效,但在处理细粒度任务时存在不足。例如,预训练的视觉编码器(如CLIP)可能会忽略图像中的关键细节,如物体颜色或小目标位置,导致模型在某些任务上表现不佳。同时,虽然现有的统一架构模型(如Fuyu)简化了流程,但需要大量数据和计算资源来训练,且性能仍落后于组合式模型。
HaploVL的出现旨在解决上述问题。它采用单一Transformer架构,通过动态融合文本和视觉信息,使文本嵌入能够“捕捉”所需的视觉线索,同时显著减少了对训练数据的需求。在性能方面,HaploVL不仅能够与现有的组合式模型相媲美,而且在细粒度视觉理解任务上表现出色。
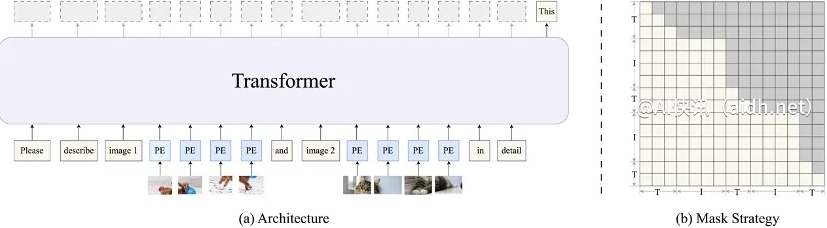
HaploVL的架构设计别具匠心。它通过多模态嵌入层直接对图像和文本进行编码,并在模型前端设置一个预解码器(视觉知识引擎),用于动态融合图文信息。这一设计类似于“雷达”,能够扫描图像中的细节,并捕捉图像内部的关联和多图之间的时序关系。后解码器(语言生成引擎)则基于融合后的特征生成自然语言回复,继承了大语言模型的语言能力,能够快速学习多模态关联并生成逻辑连贯的回答。
HaploVL的训练方法也富有创新。它采用两阶段训练方法,首先在预训练阶段对模型进行初始化,然后在微调阶段对特定任务进行优化。这种训练方式不仅提高了模型的泛化能力,还减少了对大规模数据集的依赖。
在实验中,HaploVL在多项多模态基准测试中展现出优异的性能,尤其在细粒度视觉理解任务上。例如,在边缘物体感知和推理任务中,HaploVL能够准确识别图像中的高亮区域,并生成与之相关的自然语言描述。这种能力在实际应用中具有重要意义,例如在自动驾驶、智能安防等领域,细粒度视觉理解有助于系统更准确地感知环境并做出决策。
代码链接: https://github.com/Tencent/HaploVLM
Arxiv论文链接: https://arxiv.org/abs/2503.14694
© 版权声明:
文章版权归作者所有,未经允许请勿转载。
本文地址:https://aidh.net/kuaixun/0ittrh4s
暂无评论...


















