AI导航 5000+ AI工具提升你的生产力
没有数据!等待你的参与哦 ^_^












加载中...
AI写作工具















加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
AI图片工具





加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
AI视频工具
没有内容
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
AI语音生成
















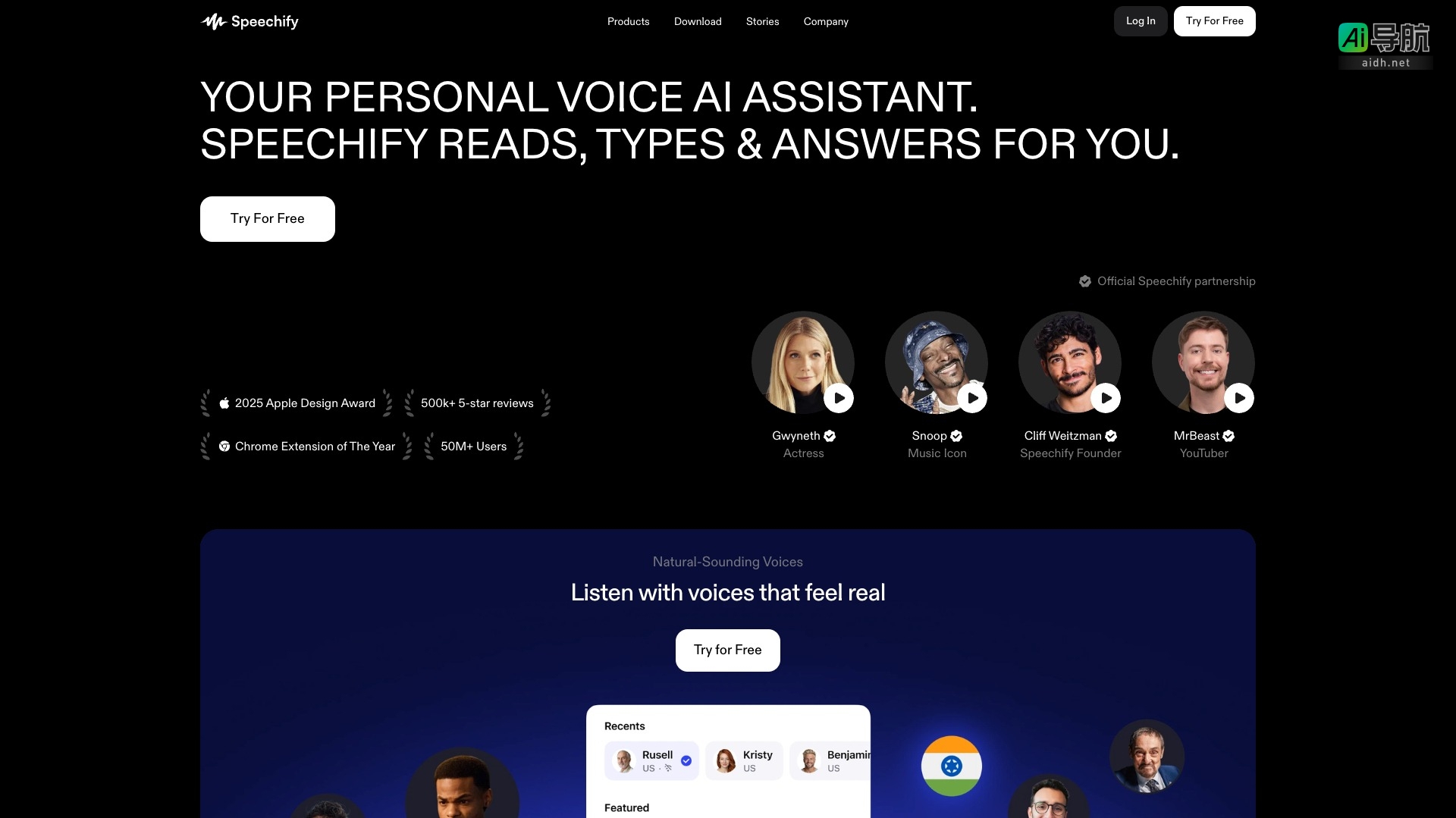

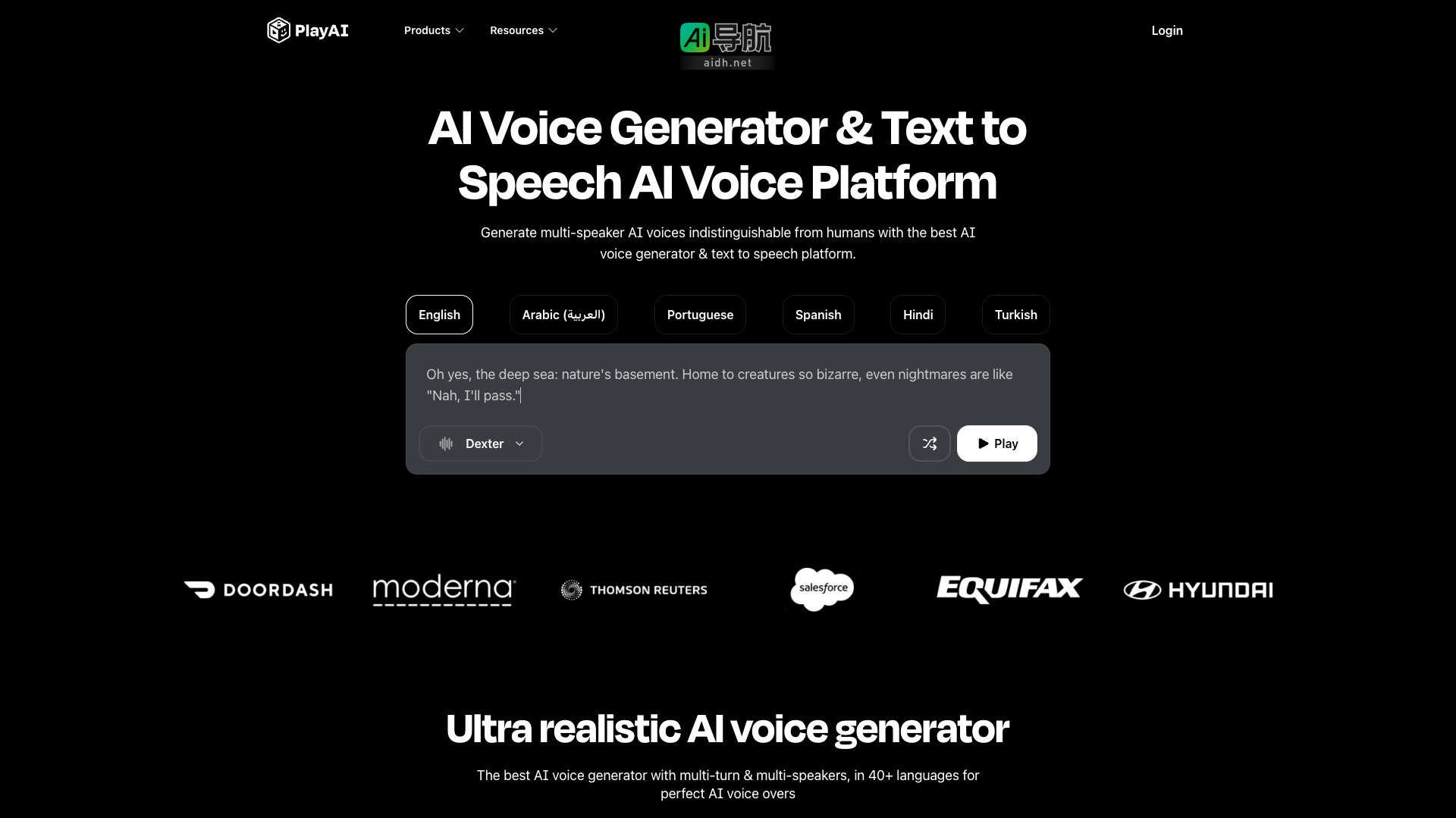

加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
AI办公软件
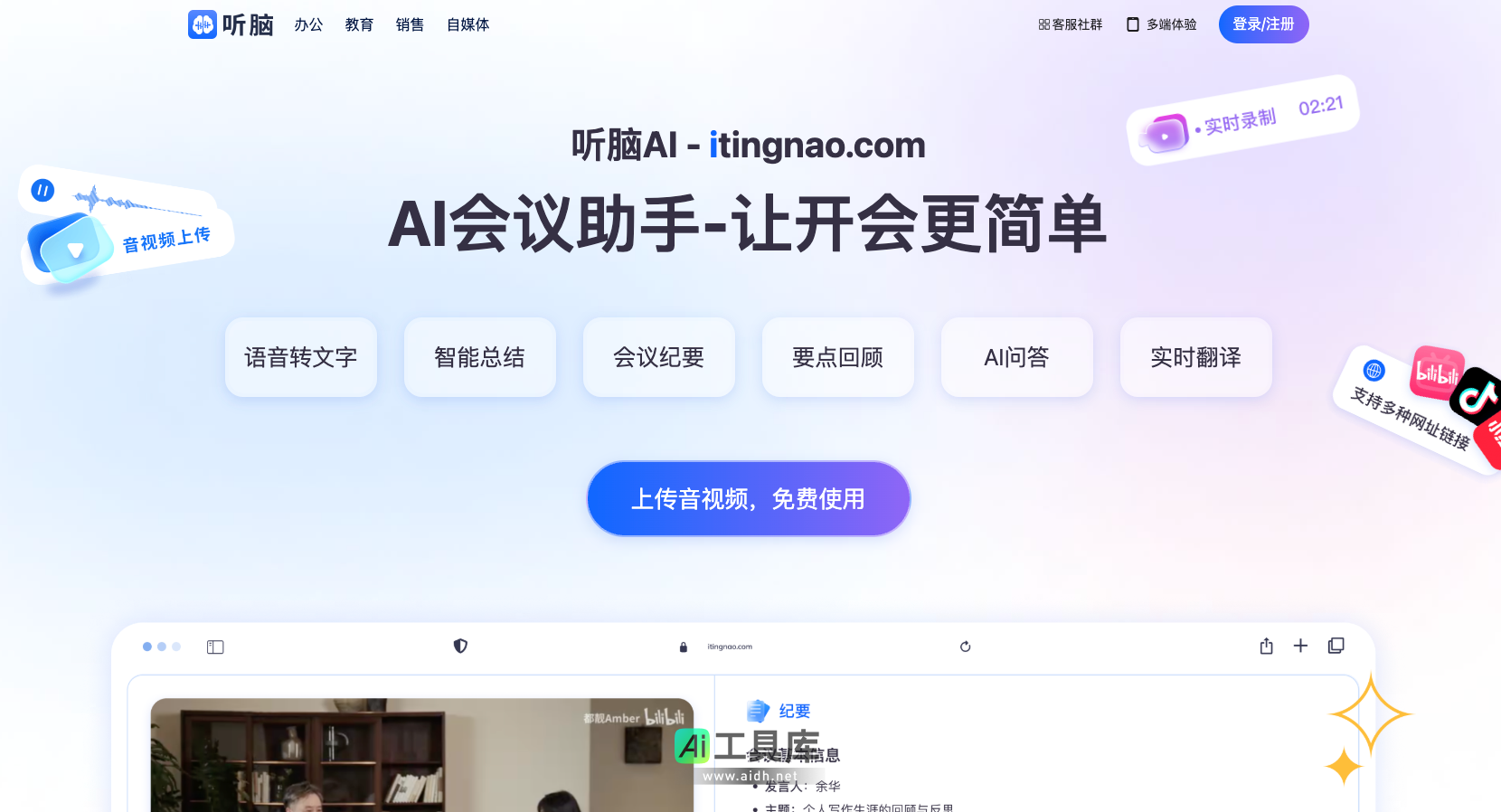

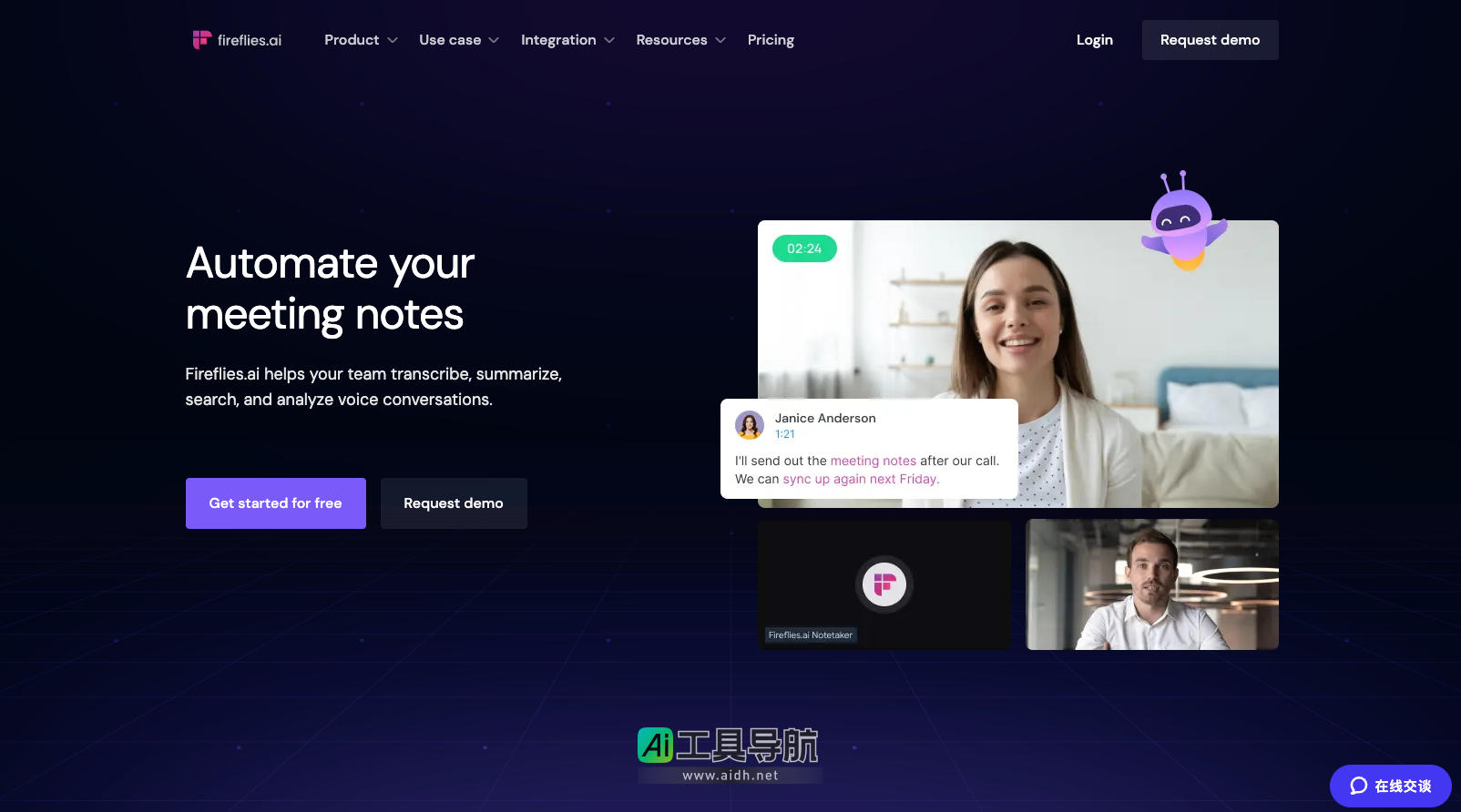

















加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
AI对话聊天
没有内容
加载中...
加载中...
加载中...






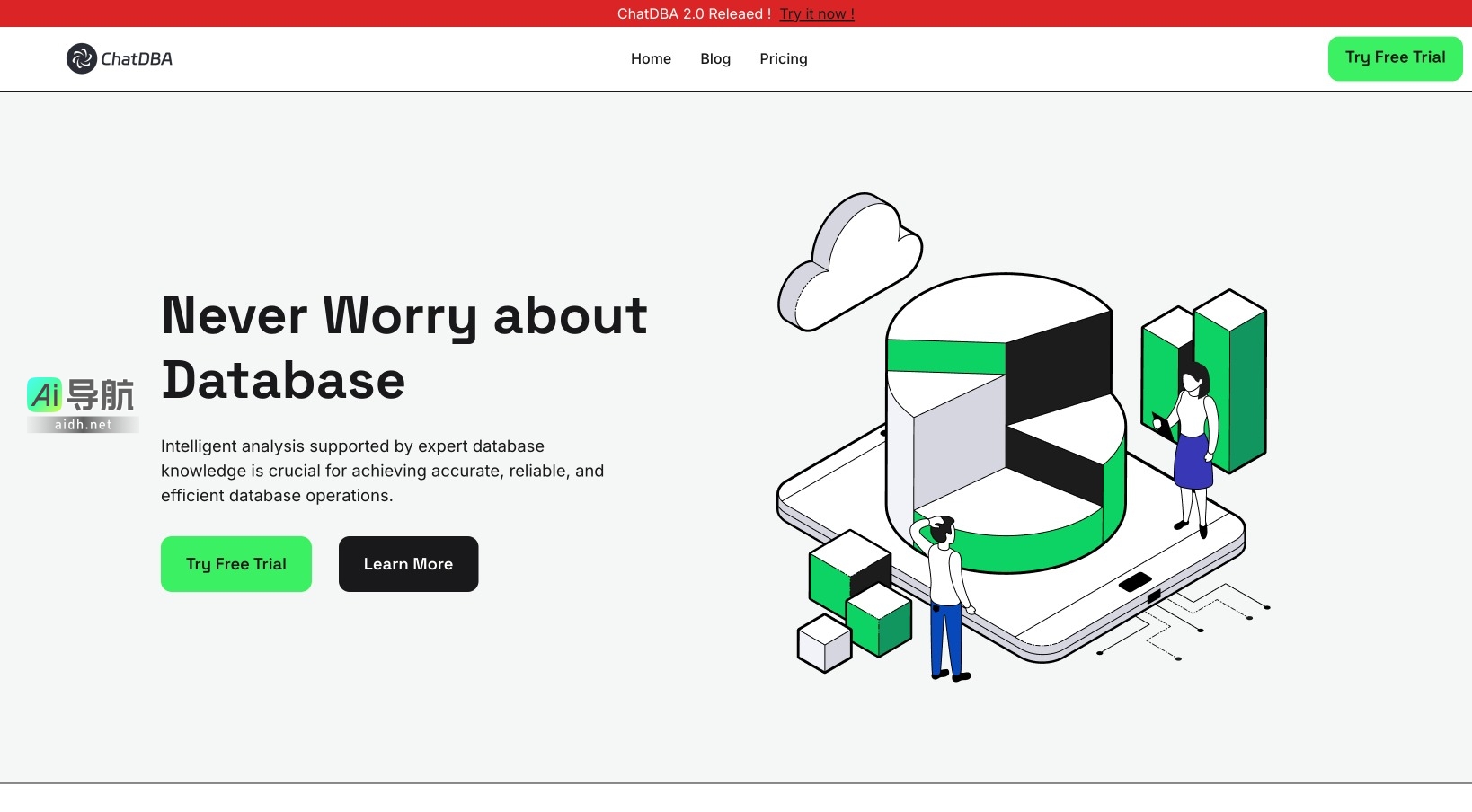

AI搜索引擎
查看更多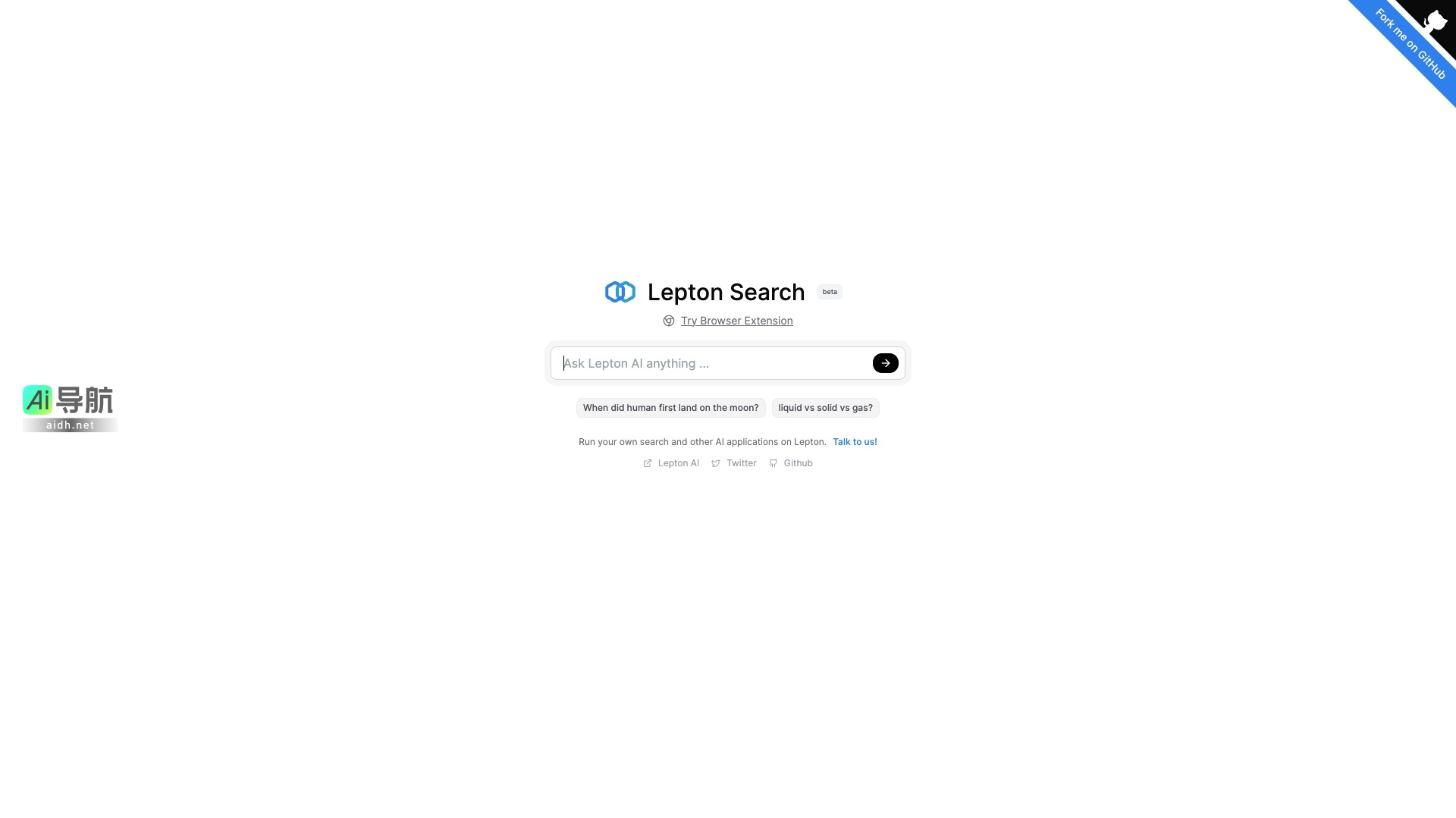

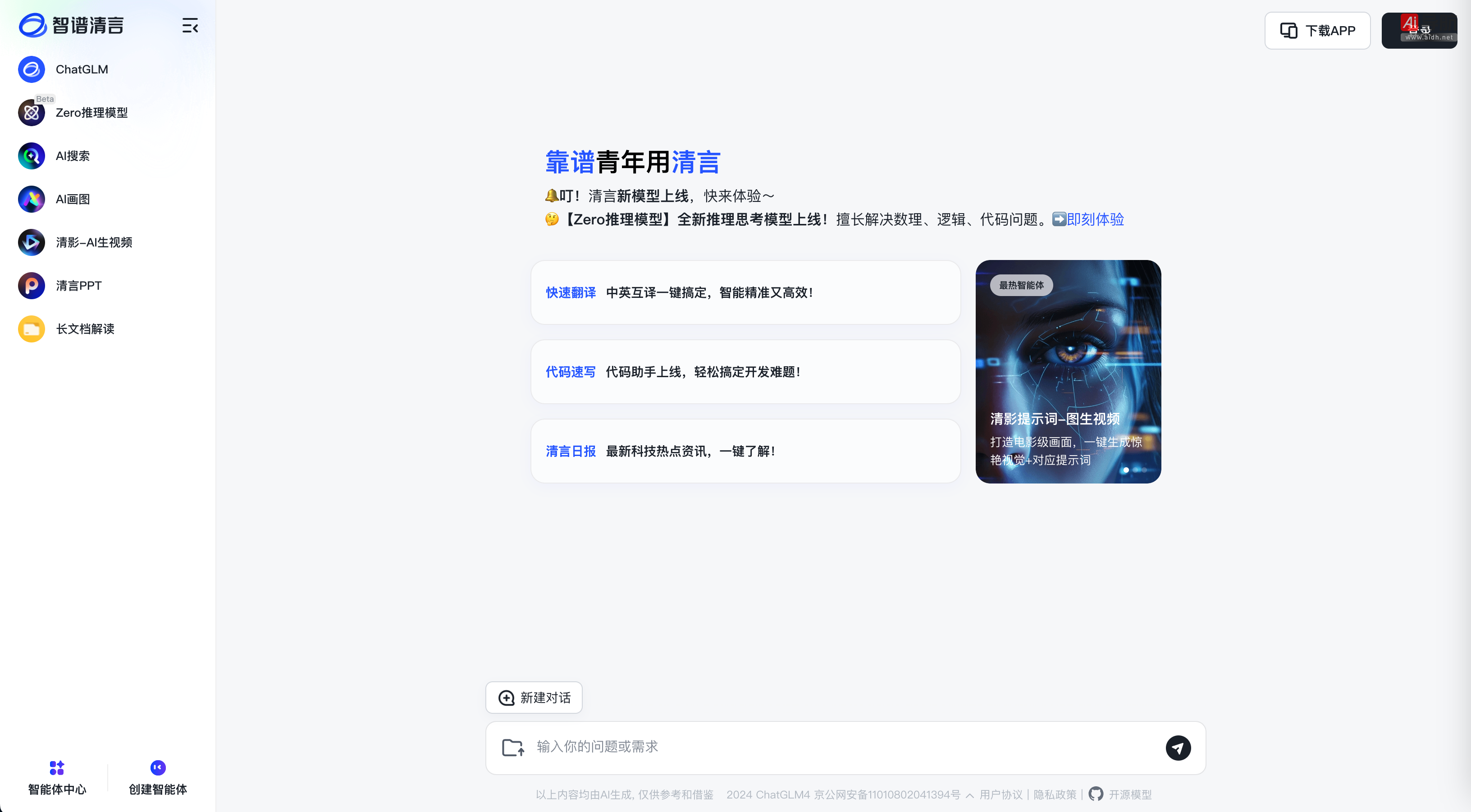

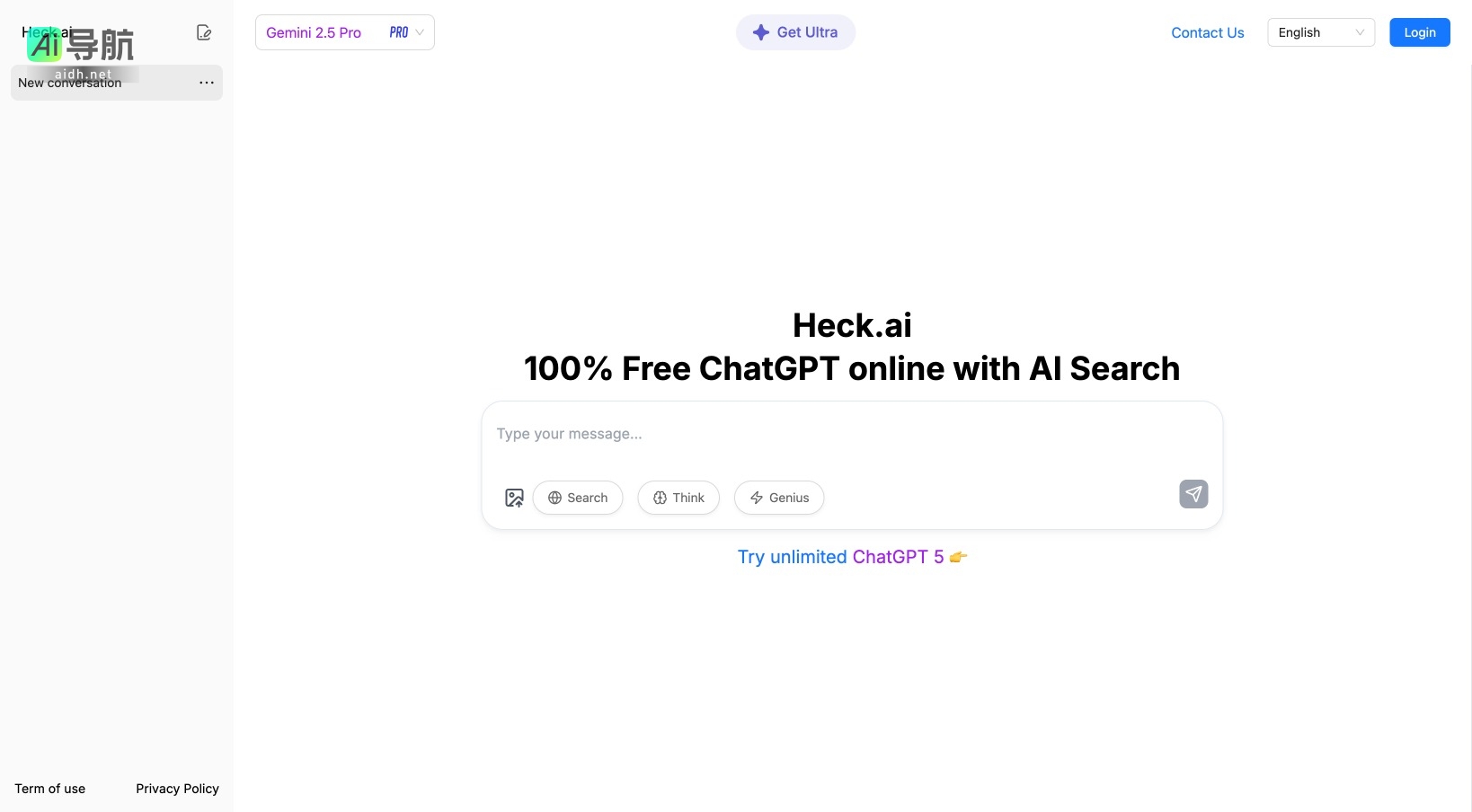













AI工具集


















加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
AI设计软件








加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
AI大模型




加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
加载中...
AI开放平台


















加载中...
加载中...
加载中...
友情链接
AI导航(aidh.net)汇集全球最新AI工具的集合类展示平台!收录国内外众多好用的AI工具和软件,涵盖AI写作工具、AI绘画工具、AI图片生成器与AI抠图工具、AI视频剪辑工具、AI音乐生成器、AI语音识别、AI编程开发、AI设计工具、AI对话聊天等丰富的AI类别,同时还有AI办公工具、AI游戏制作、AI营销、AI数字人、AI客服等各类工具大全。使用AI导航,开启高效工作、享受人工智能给生活带来的乐趣吧!


 浙公网安备33010502012189号
浙公网安备33010502012189号